Flink architecture¶
Update
- Created 2018
- Updated 11/2024 - review done.
- 12/2024: move fault tolerance in this chapter
Once Flink is started (for example with the docker image), Flink Dashboard http://localhost:8081/#/overview presents the execution reporting:
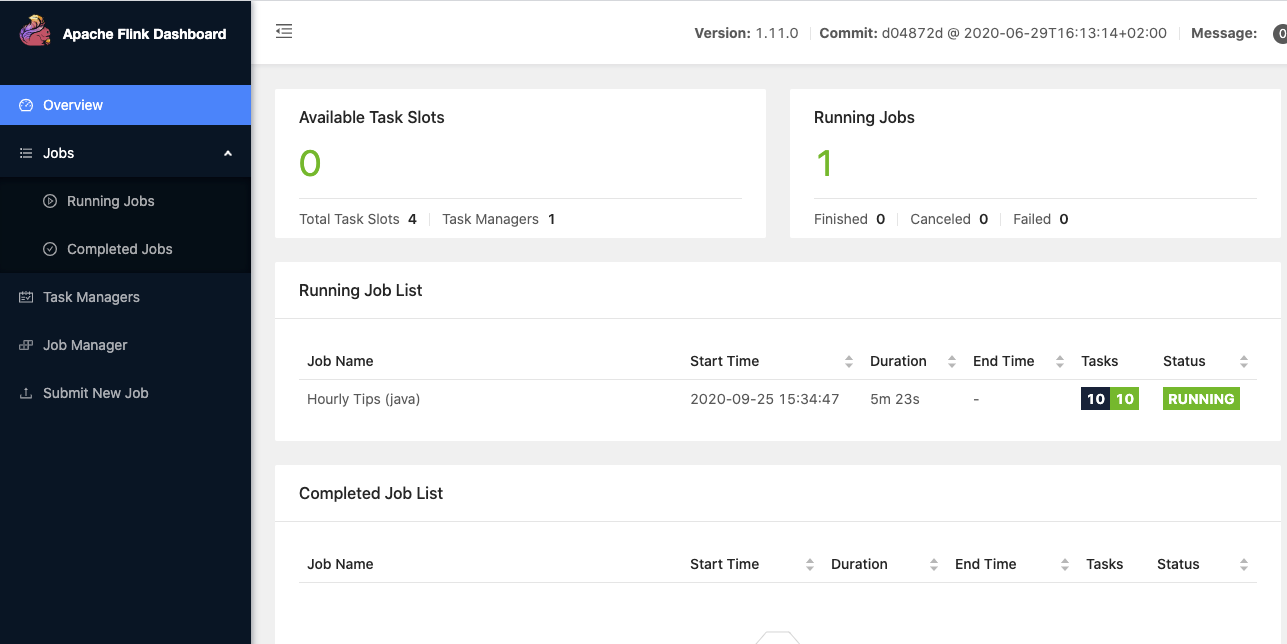
The execution is from one of the training examples, the number of task slot was set to 4, and one job is running.
Spark Streaming is using microbatching which is not a true real-time processing while Flink is a RT engine. Both Flink and Spark support batch processing.
Network Stack¶
The Flink network stack helps connecting work units across TaskManagers using Netty. Flink uses a credit-based flow control for managing buffer availability and preventing backpressure.