AWS Lambda¶
This document is a quick summary of the AWS Lambda technology, links to interesting content, labs, and sharing some best practices.
Info
Created 11/2023 - Updated 01/29/2024
Introduction¶
With AWS Lambda, we can run code without provisioning or managing servers or containers.
Upload the source code, and Lambda takes care of everything required to run and scale the code with high availability.
- Getting started tutorial with free tier
-
Pay only for what we use: # of requests and CPU time, and the amount of memory allocated.
-
A Lambda function has three primary components – trigger, code, and configuration.

- Triggers describe when a Lambda function should run. A trigger integrates the Lambda function with other AWS services, enabling to run the Lambda function in response to certain API calls that occur in the AWS account.
- An execution environment manages the processes and resources that are required to run the function.
- Configuration includes compute resources, execution timeout, IAM roles (lambda_basic_execution)...
Lambda Execution environment¶
-
The execution environment follows the life cycle as defined below (time goes from left to right):
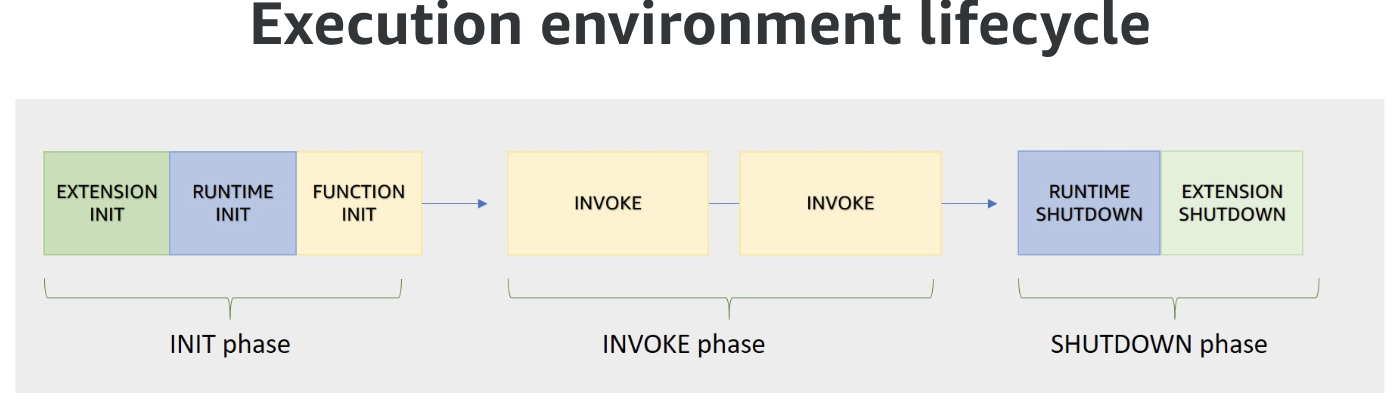
- In the Init phase Lambda creates or unfreezes an execution environment with the configured resources, downloads the code for the function and all the needed layers, initializes any extensions, initializes the runtime, and then runs the function’s initialization code. After init, the environment is 'Warm'. The extension and runtime inits is part of the
cold start(<1s). - In the Invoke phase Lambda invokes the function handler. After the function runs to completion, Lambda prepares to handle another function invocation.
- During Shutdown phase: Lambda shuts down the runtime, alerts the extensions to let them stop cleanly, and then removes the environment.
- In the Init phase Lambda creates or unfreezes an execution environment with the configured resources, downloads the code for the function and all the needed layers, initializes any extensions, initializes the runtime, and then runs the function’s initialization code. After init, the environment is 'Warm'. The extension and runtime inits is part of the
Lambda Extension
Lambda supports external and internal extensions. An external extension runs as an independent process in the execution environment and continues to run after the function invocation is fully processed. Can be used for logging, monitoring, integration...
- The Lambda service is split into the control plane and the data plane. The control plane provides the management APIs (for example,
CreateFunction,UpdateFunctionCode). The data plane is where Lambda's API resides to invoke the Lambda functions. It is HA over multi AZs in same region. -
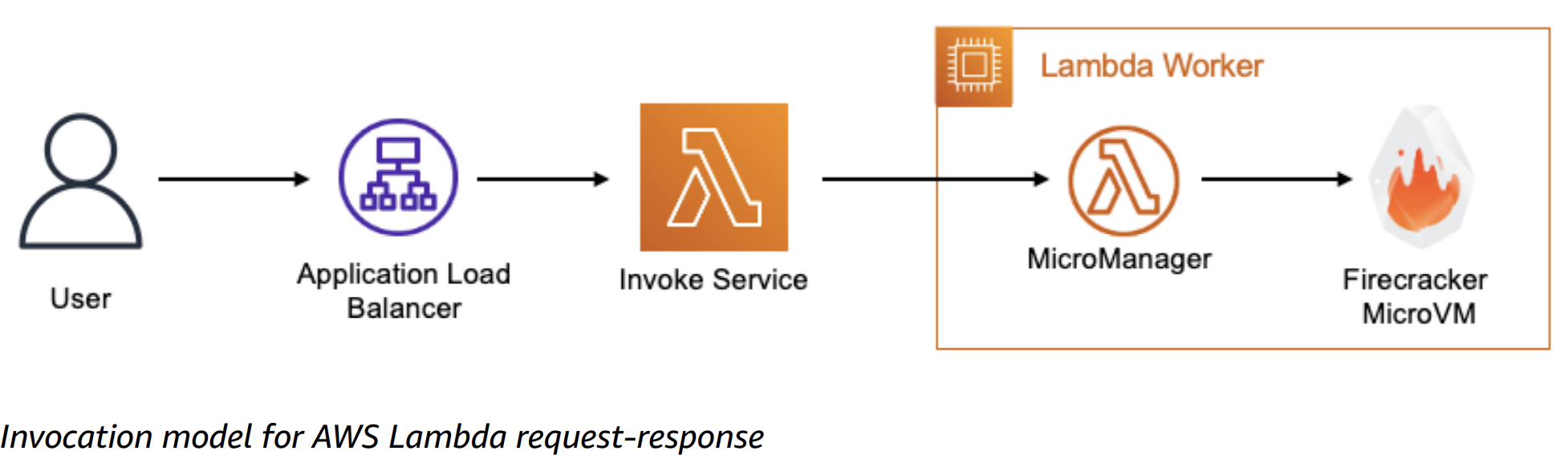
Lambda Workers are bare metal Amazon EC2 Nitro instances which are launched and managed by Lambda in a separate isolated AWS account which is not visible to customers. Each workers has one to many Firecraker microVMs. There is no container engine. Container image is just for packaging the lambda code as zip does.
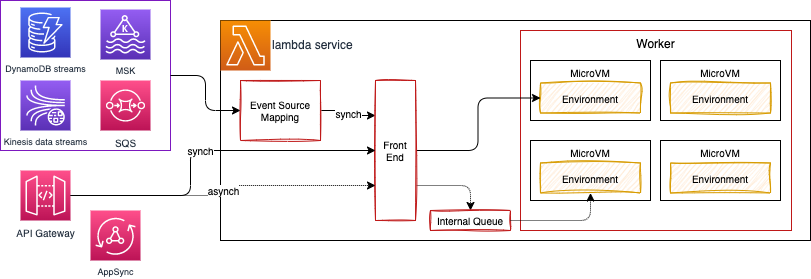
- Synchronous calls is used for immediate function response, with potential errors returned to the caller. It may return throttles when we hit the concurrency limit.
- Asynchronous calls return an acknowledgement message. Event payloads are always queued for processing before invocation. Internal SQS queue persists messages for up to 6 hours. Queued events are retrieved in batches by Lambda’s poller fleet. The poller fleet is a group of Amazon EC2 instances whose purpose is to process queued event invocations which have not yet been processed. When an event fails all processing attempts, it is discarded by Lambda. The dead letter queue (DLQ) feature allows sending unprocessed events from asynchronous invocations to an Amazon SQS queue or an Amazon SNS topic defined by the customer. Asynchronous processing should be more scalable.
- Event source mapping is used to pull messages from different streaming sources and then synchronously calls the Lambda function. It reads using batching and send all the events as argument to the function. If the function returns an error for any of the messages in a batch, Lambda retries the whole batch of messages until processing succeeds or the messages expire. It supports error handling.
- If the service is not available. Callers may queue the payload on client-side to retry. If the invoke service receives the payload, the service attempts to identify an available execution environment for the request and passes the payload to that execution environment to complete the invocation. It may lead to create this execution environment.
-
There is at least one runtime which matches the programming language (Java, Node.js, C#, Go, or Python).
- To reuse code in more than one function, consider creating a Layer and deploying it. A layer is a ZIP archive that contains libraries, a custom runtime, or other dependencies.
-
Lambda supports versioning and developer can maintain one or more versions of the lambda function. We can reduce the risk of deploying a new version by configuring the alias to send most of the traffic to the existing version, and only a small percentage of traffic to the new version. Below is an example of creating one Alias to version 1 and a routing config with Weight at 30% to version 2. Alias enables promoting new lambda function version to production and if we need to rollback a function, we can simply update the alias to point to the desired version. Event source needs to use Alias ARN for invoking the lambda function.
aws lambda create-alias --name routing-alias --function-name my-function --function-version 1 --routing-config AdditionalVersionWeights={"2"=0.03} -
Each lambda function has a unique ARN.
- Deployment package is a zip or container image.
Scaling¶
Lambda invokes the code in a secure and isolated execution environment, which needs to be initialized and then executes the function code for the unique request it handles. Second request will not have the initialization step. When requests arrive, Lambda reuses available execution environments, and creates new ones if necessary.
The number of execution environments determines the concurrency. Limited to 1000 by default.
Concurrency (# of in-flight requests the function is currently handling) is subject to quotas at the AWS Account/Region level. See quotas documentation.
When the number of requests decreases, Lambda stops unused execution environments to free up scaling capacity for other functions.
Use the Lambda CloudWatch metric named ConcurrentExecutions to view concurrent invocations for all or individual functions. To estimate concurrent requests use: Request per second * Avg duration in seconds = concurrent requests
Lambda scales to very high limits, but not all account's concurrency quota is available immediately, so requests could be throttled for a few minutes in case of burst.
There are two scaling quotas to consider with concurrency. Account concurrency quota (1000 per region) and burst concurrency quota (from 500 to 3000 per min per region). Further requests are throttled, and lambda returns HTTP 429 (too many requests).
It is possible to use Reserved concurrency, which splits the pool of available concurrency into subsets. A function with reserved concurrency only uses concurrency from its dedicated pool. This is helpful to avoid one lambda function to take all the concurrency quota and impact other functions in the same region. No extra charges.
For functions that take a long time to initialize, or that require extremely low latency for all invocations, provisioned concurrency enables to pre-initialize instances of the function and keep them running at all times.
Use concurrency limit to guarantee concurrency availability for a function, or to avoid overwhelming a downstream resource that the function is interacting with.
If the test results uncover situations where functions from different applications or different environments are competing with each other for concurrency, developers probably need to rethink the account segregation strategy and consider moving to a multi-account strategy.
Memory is the only setting that can impact performance. Both CPU and I/O scale linearly with memory configuration. We can allocate up to 10 GB of memory to a Lambda function. In case of low performance, start by adding memory to the lambda.

- AWS Lambda Power Tuning tool to find the right memory configuration.
- Understanding AWS Lambda scaling and throughput - an AWS blog.
Networking¶
- Lambda functions always operate from an AWS-owned VPC. By default, the function has the full ability to make network requests to any public internet addresses — this includes access to any of the public AWS APIs.
- Only enable the functions to run inside the context of a private subnet in a VPC, when we need to interact with a private resource located in a private subnet. In this case we need to enable internet outbound connection, like NAT, network policies, IGW.
- When connecting a Lambda function to a VPC, Lambda creates an elastic network interface, ENI, for each combination of subnet and security group attached to the function.
Private resource within VPC¶
![]
API Gateway integration¶
Resources defined as API in Amazon API Gateway may define one or more methods, such as GET or POST which integration routes requests to a Lambda function. We can add a Trigger to a Lambda to get a HTTP API integration from the API Gateway. We configure API Gateway to pass the body of the HTTP request as-is.
The event format is defined here.
Edge Function¶
When we need to customize the CDN content, we can use Edge Function to run closer to the end users.
CloudFront provides two types: CloudFront functions or Lambda@Edge.
Edge can be used for:
- Website security and privacy.
- Dynamic web application at the Edge.
- Search engine optimization (SEO).
- Intelligently route across origins and data centers.
- Bot mitigation at the Edge.
- Real-time image transformation.
- User authentication and authorization.
Criteria to use lambda¶
Technical constraints¶
- Per region deployment.
- Must run under 15 min.
- Memory from 128MB to 10GB.
- Maximum 1000 concurrent calls.
- Code in compressed zip should be under 50MB and 250MB uncompressed.
- Disk capacity for /tmp is limited to 10GB.
Design constraints¶
- When migrating existing application review the different design patterns to consider.
- Think about co-existence with existing application and how API Gateway can be integrated to direct traffic to new components (Lambda functions) without disrupting existing systems. With API Gateway developer can export the SDK for the business APIs to make integration easier for other clients, and can use throttling and usage plans to control how different clients can use the API.
- Do cost comparison analysis. For example API Gateway is pay by the requests, while ALB is priced by hours based on the load balance capacity units used per hour. Lambda is also per request based.
- Not everything fits into the function design. Assess if it makes sense to map REST operations in the same handler. AWS Lambda Powertools has a APIGatewayRestResolver that makes the code neat with api being defined with annotation: see Lambda DynamoDB example
- Assess when to use Fargate when the application is in container, and may run for a long time period. Larger packaging may not be possible to run on Lambda. Applications that use non HTTP end point, integrate to messaging middleware with Java based APIs are better fit for Fargate deployment.
Security¶
As a managed service, AWS manages the underlying infrastructure and foundation services, the operating system, and the application platform. Developers need to ensure code, libraries, configuration, IAM are well set. Some security considerations:
- Data privacy with encryption at rest with customer managed Key, encryption in transit, access control.
- Function runtime environment variables are secured by encryption using a Lambda-managed KMS key (named
aws/lambda). TheCreateFunctionAPI orUpdateFunctionConfigurationmay use KMS Keys. - AWS X-Ray also encrypts data by default.
- TLS1.2 for all public APIs.
- Run on EC2 with Nitro System for better security isolation.
-
Code releases go through security review and penetration testing. It provides a code signing feature to ensure only trusted code is run in the Lambda function.
-
Lambda also supports function URLs, a built-in HTTPS endpoint for invoking functions. No need for API Gateway and ALB.
- Each Lambda exec environment includes a writeable /tmp folder: files written within it, remain for the lifetime of the execution environment.
-
Also to enable the Lambda function to access resources inside the private VPC, we must provide additional VPC-specific configuration information that includes VPC subnet IDs and security group IDs and the
AWSLambdaVPCAccessExecutionRolepolicy. AWS Lambda uses this information to set up elastic network interfaces (ENIs) that enable the function to connect securely to other resources in the VPC.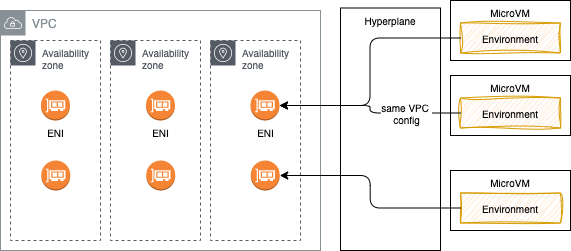
As Lambda function always runs inside a VPC owned by the Lambda service, the function accesses resources in our VPC using a Hyperplane ENI. Hyperplane ENIs provide NAT capabilities from the Lambda VPC to our account VPC using VPC-to-VPC NAT (V2N).
If it runs out of IP@ then we will have EC2 error types like
EC2ThrottledExceptionand the function will not scale. So be sure to have multiple AZ/ subnets and enough IP@. -
For the function to access the internet, route outbound traffic to a NAT gateway in one public subnet in the VPC.
-
To establish a private connection between the VPC and Lambda, create an interface VPC endpoint (using AWS PrivateLink). Traffic between the VPC and Lambda does not leave the AWS network.
aws ec2 create-vpc-endpoint --vpc-id vpc-ec43eb89 --vpc-endpoint-type Interface --service-name \ com.amazonaws.us-west-2.lambda --subnet-id subnet-abababab --security-group-id sg-1a2b3c4d
Endpoint policy can be attached to the interface endpoint to add more control on which resource inside the VPC can access the lambda function (Principal = user, Allow lambda:InvokeFunction on resource with the function arn).
Policies and roles¶
With Lambda functions, there are two sides that define the necessary scope of permissions – permission to invoke the function (using resource policies), and permission of the Lambda function itself to act upon other services (IAM execution role).
The execution role must include a trust policy that allows Lambda to “AssumeRole” so that it can take that action for another service.
Lambda resource policies are :
- Associated with a "push" event source such as Amazon API Gateway.
- Created when we add a trigger to a Lambda function.
- Allows the event source to take the
lambda:InvokeFunctionaction.
We can use Parameter Store, from System Manager, to reference Secrets Manager secrets, creating a consistent and secure process for calling and using secrets and reference data in the code and configuration script.
Monitoring¶
AWS Lambda automatically monitors Lambda functions and reports metrics through Amazon CloudWatch. To help monitoring the code as it executes, Lambda automatically tracks the number of requests, the latency per request, and the number of requests resulting in an error and publishes the associated metrics. Developer can leverage these metrics to set custom CloudWatch alarms.
Distributed tracing helps pinpoint where failures occur and what causes poor performance. Tracing is about understanding the path of data as it propagates through the components of the application.
Amazon CloudWatch Lambda Insights is a monitoring and troubleshooting solution for serverless applications running on Lambda. Lambda Insights collects, aggregates, and summarizes system-level metrics. It also summarizes diagnostic information such as cold starts and Lambda worker shutdowns to help isolate issues with the Lambda functions and resolve them quickly.
X-Ray provides an end-to-end view of requests as they travel through the application and the underlying components. Developer can use AWS X-Ray to visualize the components of the application, identify performance bottlenecks, and troubleshoot requests that resulted in an error.
See this article: Operating Lambda with logging and custom metrics.
Custom metrics¶
Custom metrics can be used for tracking statistics in the application domain, instead of measuring performance related to the Lambda function. Use AWS SDK with the CloudWatch library and the putMetricData API.
Javascript Code Example
const AWSXRay = require('aws-xray-sdk-core')
const AWS = AWSXRay.captureAWS(require('aws-sdk'))
const cloudwatch = new AWS.CloudWatch()
exports.putMetric = async (name, unit = MetricUnit.Count, value = 0, options) => {
try {
log.debug(`Creating custom metric ${name}`)
const metric = buildMetricData(name, unit, value, options)
await cloudwatch.putMetricData(metric).promise()
} catch (err) {
log.error({ operation: options.operation !== undefined ? options.operation : 'undefined_operation', method: 'putMetric', details: err })
throw err
}
}
const buildMetricData = (name, unit, value, options) => {
let namespace = 'MonitoringApp',
service = process.env.SERVICE_NAME !== undefined ? process.env.SERVICE_NAME : 'service_undefined'
if (options) {
if (options.namespace !== undefined) namespace = options.namespace
if (options.service !== undefined) service = options.service
delete options.namespace
delete options.service
}
const metric = {
MetricData: [
{
MetricName: name,
Dimensions: buildDimensions(service, options),
Timestamp: new Date(),
Unit: unit,
Value: value
},
],
Namespace: namespace
};
return metric
}
Metrics are in namespace in CloudWatch.
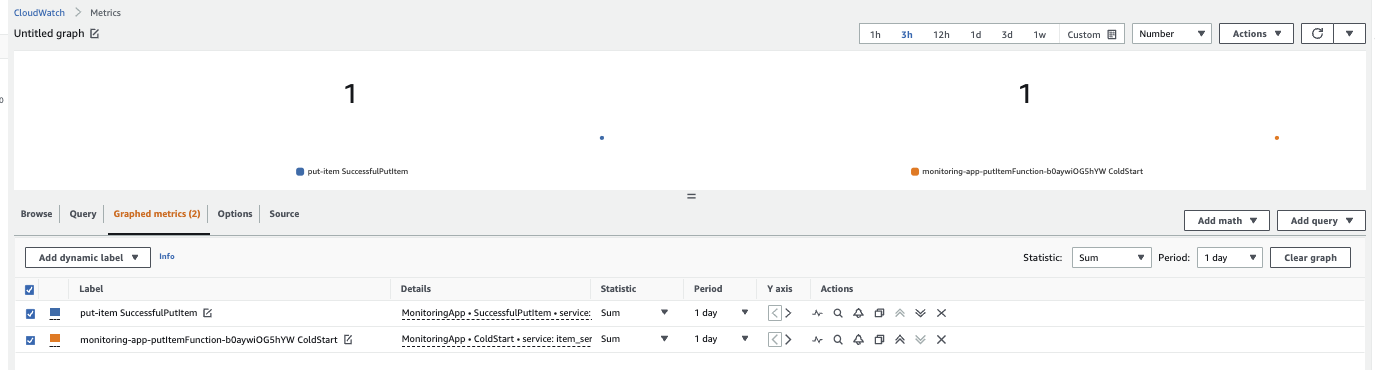
But those synchronous calls consumes resources and adds latency to the lambda's response. To overcome this overhead, we can adopt an asynchronous strategy to create these metrics. This strategy consists of printing the metrics in a structured or semi-structured format as logs to Amazon CloudWatch Logs and have a mechanism in background processing these entries based on a filter pattern that matches the same entry that was printed.
Using the Embedded Metric Format¶
EMF logging code example
const { createMetricsLogger, Unit } = require("aws-embedded-metrics")
exports.logMetricEMF = async (name, unit = Unit.Count, value = 0, dimensions) => {
try {
const metrics = createMetricsLogger()
metrics.putDimensions(buildEMFDimensions(dimensions))
metrics.putMetric(name, value, unit)
metrics.setNamespace(process.env.AWS_EMF_NAMESPACE !== undefined ? process.env.AWS_EMF_NAMESPACE : 'aws-embedded-metrics')
log.debug(`Logging custom metric ${name} via Embbeded Metric Format (EMF)`)
log.debug(metrics)
await metrics.flush()
} catch (err) {
log.error({ operation: dimensions.operation !== undefined ? options.dimensions : 'undefined_operation', method: 'logMetricEMF', details: err })
throw err
}
}
const buildEMFDimensions = (dimensions) => {
let service = process.env.SERVICE_NAME !== undefined ? process.env.SERVICE_NAME : 'service_undefined'
if (dimensions) {
if (dimensions.service !== undefined) service = dimensions.service
delete dimensions.namespace
delete dimensions.service
}
return dimensions
}
Find cold starts¶
Example of cloudwatch insight query:
filter @type = "REPORT"
| parse @message /Init Duration: (?<init>\S+)/
| stats count() as total, count(init) as coldStarts,
median(init) as avgInitDuration,
max(init) as maxInitDuration,
avg(@maxMemoryUsed)/1000/1000 as memoryused
by bin(5min)
Hands-on¶
Getting Started¶
Basic getting started
In a serverless deployment, developer needs to provide all the necessary components:
- Code, bundled with any necessary dependencies
-
CloudFormation template: (AWS SAM helps building this CF template).
-
Can start from a blueprint
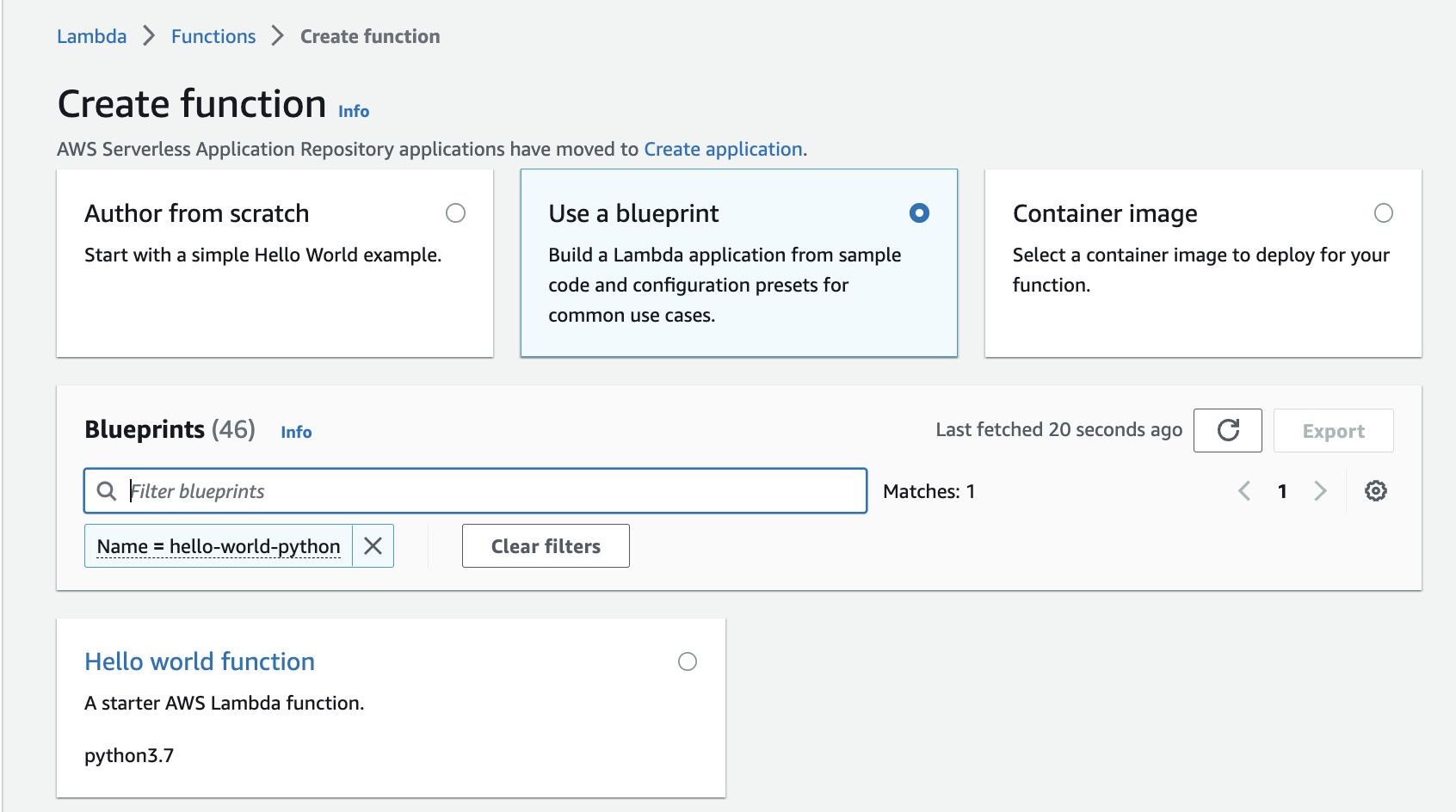
-
To get the function to upload logs to cloudWatch, select an existing IAM role, or create a new one with the right policy:
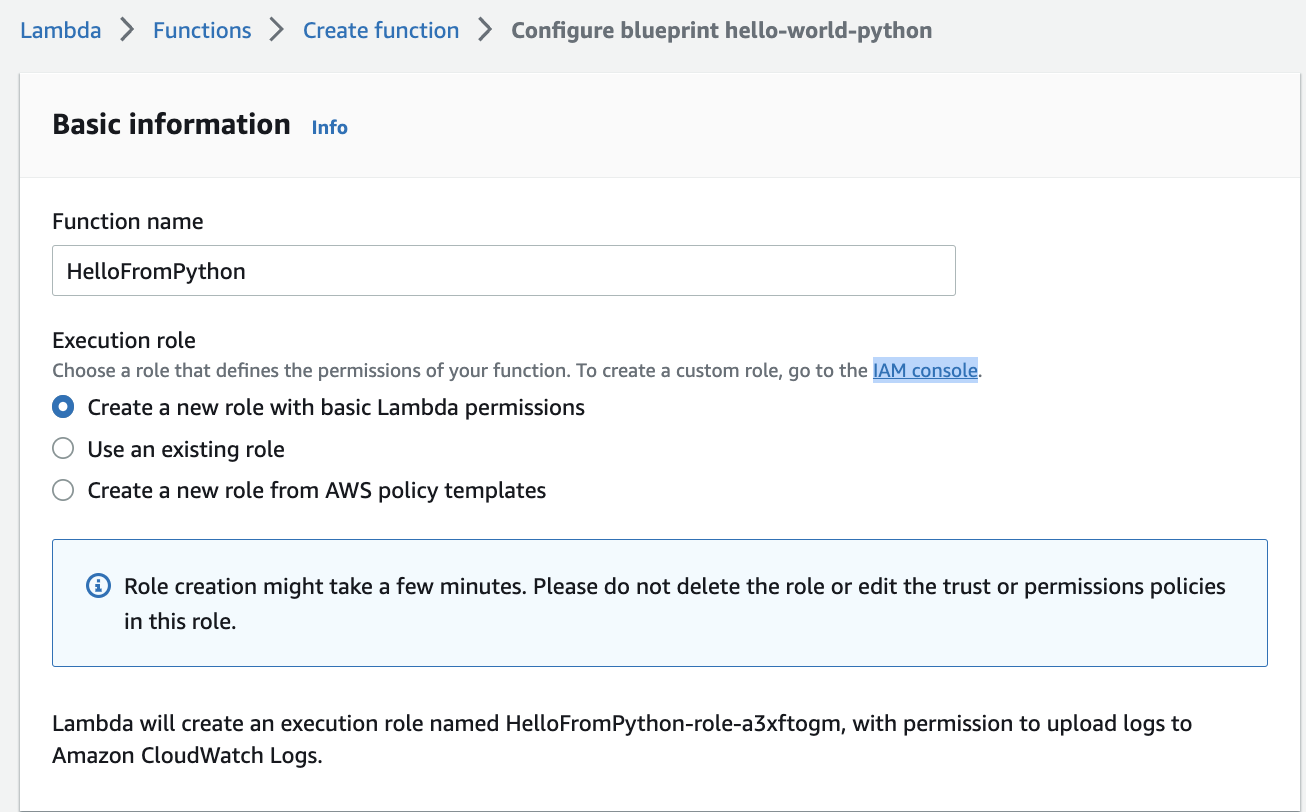
Here the example of role created
-
Add the code as an implementation of an handler function:
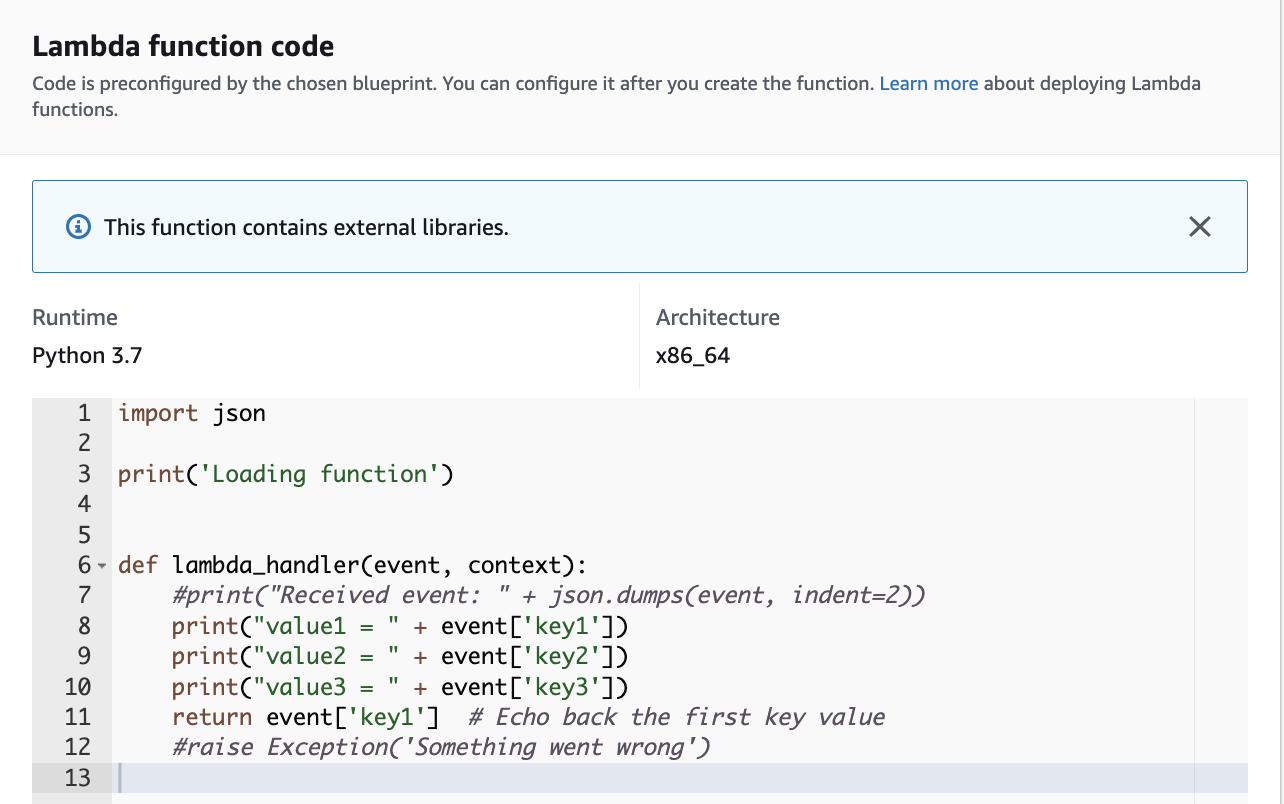
-
Create a test event (a request) and run the test and get the resources and logs output.
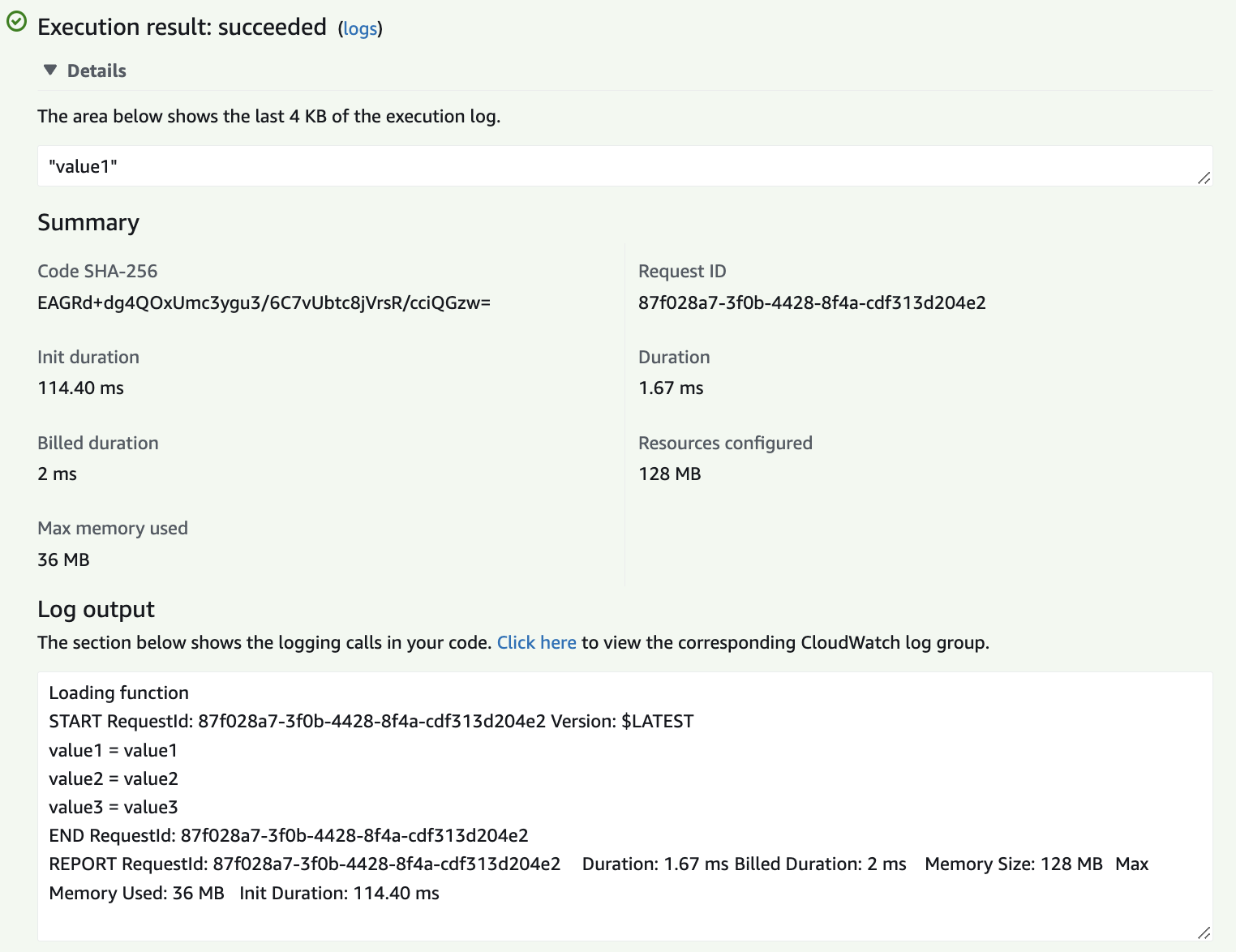
-
Verify configuration and monitoring in CloudWatch.
Python function with dependencies¶
It is common to have a function that needs libraries not in the standard Python 3.x environment. The approach is to use a zip file as source of the dependencies. The process to build such zip can be summarized as:
lambdais the folder with code and future dependencies. It has arequirements.txtfile to define dependencies.- do a
pip install --target ./python/lib/ -r requirements.txt -
zip the content of the package directory in a zip in the lambda folder
cd python zip -r ../lambda-layer.zip . -
The zip can be used as a layer, so reusable between different lambda functions. Upload the zip to a
S3bucket and create a layer in the Lambda console, referencing the zip in S3 bucket.As an alternate here is a CDK declaration for the powertool dependencies:
powertools_layer = aws_lambda.LayerVersion.from_layer_version_arn( self, id="lambda-powertools", layer_version_arn=f"arn:aws:lambda:{env.region}:017000801446:layer:AWSLambdaPowertoolsPythonV2:61" ) ... acm_lambda = aws_lambda.Function(self, 'CarMgrService', runtime=aws_lambda.Runtime.PYTHON_3_11, layers=[powertools_layer], ... -
A layer can be added to any lambda function, then the libraries included in the layer can be imported in the code. Example is the XRay tracing capability in Python.
project with modules
When the Lambda code is organized with different modules, we may get Unable to import module 'app':... when running the function in the Lambda runtime. Here is an example:
from .acm_model import AutonomousCar, AutonomousCarEvent
The folder tree:
src
├── carmgr
│ ├── __init__.py
│ ├── acm_model.py
│ └── app.py
└── requirements.txt
Add the cdk:
acm_lambda = aws_lambda.Function(self, 'CarMgrService',
code= aws_lambda.Code.from_asset(path="../src/",
handler='carmgr.app.handler',
-
We can also add the lambda-function code in the zip and modify the existing function, something like:
zip lambda-layer.zip lambda-handler.py aws lambda update-function-code --function-name ApigwLambdaCdkStack-SageMakerMapperLambda2E...C --zip-file file://lambda-layer.zip
See the the from-git-to-slack-serverless repository for a Lambda example in Python using SAM for deployment and autonomous-car-mgr project for cdk based deployment and more module integration.
Java based function¶
We can run java code in Lambda and implement different handlers.
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
public class HandlerWeatherData implements RequestHandler<WeatherData,WeatherData>{
@Override
public WeatherData handleRequest(WeatherData event, Context context) {
Code can be uploaded as jar or zip to a S3 bucket, and CloudFormation template or CDK can define the lambda function.
In the Java code template in folder the Lambda processes a JavaBean and we can build a docker image, push to ECR and use CDK to deploy the function.
FROM public.ecr.aws/lambda/java:11
COPY target/classes ${LAMBDA_TASK_ROOT}
COPY target/dependency/* ${LAMBDA_TASK_ROOT}/lib/
CMD [ "jbcodeforce.HandlerWeatherData::handleRequest" ]
See also the docker image lambda java.
To be sure the dependencies are used, use the build plugin in maven:
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.1.2</version>
....
See the readme for instructions.
Product documentation: Deploy Java Lambda functions with container images..
Here is a Lambda Function CDK declaration using ECR image
repository= aws_ecr.Repository.from_repository_name(self,"java-lambda-ecr-repo","jbcodeforce/java-lambda")
aws_lambda.DockerImageFunction(self,"JavaLambda",
code=aws_lambda.DockerImageCode.from_ecr(repository),
role=sm_role,
tracing=aws_lambda.Tracing.ACTIVE,
architecture=aws_lambda.Architecture.ARM_64)
Java on AWS Lambda workshop to discover best practices for Java and Lambda using GraalVM or SnapStart
CI/CD¶
Workshop: Building CI/CD pipelines for Lambda canary deployments using AWS CDK
Other personal implementations¶
- Lamdba prepared by SAM + tutorial form AWS Lambda powertool with API gateway.
- S3 to Lambda to S3 for data transformation
- Big data SaaS: lambda to call SageMaker
- cdk python for lambda, dynamoDB, api gtw, AWS powertools (autonomous car manager): a Python lambda + API gateway, dynamoDB, iam policy, Alias and version.
FAQs¶
Best practices¶
Extracted from the Top best practices and tips for building Serverless applications video
Be sure to measure concurrency correctly
Concurrency = TPS * Duration. Ex 100 Tx/s for and average duration of 500ms = so concurrency id 50, but is it takes 2s per tx, then c=200. So Optimize for duration <1 and monitor ConcurrentExecutions metric.
Lambda bursting and scaling
Burst limit may differ per region. Each new lambda invocation reuses available execution contexts, and it creates new contexts until the account concurrency limit is reached. So initial burst is subject to the account concurrency limit which may be 1000, but it then scales by +500 contexts per minute until burst limit (3000), once the burst limit is reached, all other requests are throttled. 
Reuse the execution environment properly
Initialize outside of the handler, lazy load it when needed, and cache static assets in /tmp. In Java the class constructor is only called at cold-start.
Control and limit dependencies
Include only what is needed. In java use the shade maven plugin to create a uber jar which removes duplicates. Use exclusion of jars from aws-sdk. Attach SDK in a layer.
Tell the SDK what to do
Most of the time SDK will know in which region it is, but it costs time, so prefer to use env variables and get in the code. Try to reuse connection. It can reduce CPU utilization up to 50%.
VPC - Lambda
Lambda must target private subnets and never public one. Target two subnets for HA. Do not remove created ENIs in EC2 console. Controls the VPCs, subnets and security groups the Lambda functions can target.
Lambda chaining
Avoid chaining directly lambda functions synchronously. Use Lambda destination or Step Functions.
Inject secrets safely
Inject them in environment variables, where values come in the function yaml definition.
More reading¶
- Serverless application lens: focus on how to design, deploy, and architect serverless application workloads in the AWS Cloud.
- Security overview of AWS Lambda - whitepaper
- Using an Amazon S3 trigger to invoke a Lambda function.
-
Tutorial: Resize Images on the Fly with Amazon S3, AWS Lambda, and Amazon API Gateway.
- Power tuning tool for Lambda.
- Serverless Patterns Collection (Serverlessland).
- Youtube videos - Build on serverless 2019.
- Lambda- configuring reserved concurrency
- Increasing real-time stream processing performance with Amazon Kinesis Data Streams enhanced fan-out and AWS Lambda
- Powertool for AWS Lambda - Python a developer toolkit to implement Serverless best practices and increase developer velocity.
- Powertool for AWS Lambda - Java.