Serverless¶
Info
Created 04/2023 - Updated 1/19/2024
Serverless helps organization to get to the market quickly, removing heavy lifting work like servers management. Serverless should not be lambda / function programming.
Characteristics of serverless computing¶
- No server infrastructure to provision or to manage.
- Flexible scaling: scale automatically in response to the load, and capacity defined in term of unit of work. Scale to zero too.
- Automated HA and fault tolerance.
- No idle capacity. Only charged for the total invocations of our function, and the amount of time that our function is actually running.
Serverless on AWS is supported by a lot of services:
- AWS Lambda: Function programming model. Limited by time - short executions, runs on-demand, and automated scaling. Pay per call, duration and memory used.
- DynamoDB: no sql db, with HA supported by replication across three AZs. Millions req/s, trillions rows, 100s TB storage. Low latency on read. Support event-driven programming with streams: lambda function can read the stream (24h retention). Table oriented, with dynamic attribute but primary key. 400KB max size for one document. It uses the concept of Read Capacity Unit and Write CU. It supports auto-scaling and on-demand throughput. A burst credit is authorized, when empty we get ProvisionedThroughputException. Finally it use the DynamoDB Accelerator to cache data to authorize micro second latency for cached reads. Supports transactions and bulk tx with up to 10 items.
- AWS Cognito: gives users an identity to interact with the applications.
-
AWS API Gateway: API versioning, websocket support, different environment, support authentication and authorization. Handle request throttling. Cache API response. SDK. Support different security approaches:
- IAM:
- Great for users / roles already within your AWS account
- Handle authentication + authorization
- Leverages Sig v4
- Custom Authorizer:
- Great for 3rd party tokens
- Very flexible in terms of what IAM policy is returned
- Handle Authentication + Authorization
- Pay per Lambda invocation
- Cognito User Pool:
- You manage your own user pool (can be backed by Facebook, Google login etc…)
- No need to write any custom code
- Must implement authorization in the backend
- IAM:
-
Amazon S3
- Amazon SNS & SQS: for asynchronous communication between components.
- AWS Kinesis Data Firehose
- Aurora Serverless
- AWS Step Functions
- Fargate and ECS
- Managed Service for Apache Kafka: MSK.
- Kinesis Data Stream
Lambda@Edge is used to deploy Lambda functions alongside a CloudFront CDN, it is for building more responsive applications, closer to the end user. Lambda is deployed globally. Here are some use cases: Website security and privacy, dynamic webapp at the edge, search engine optimization (SEO), intelligent route across origins and data centers, bot mitigation at the edge, real-time image transformation, A/B testing, user authentication and authorization, user prioritization, user tracking and analytics.
Getting started with serverless computing on AWS.
Container¶
A container is a standardized unit that packages the code and its dependencies together. This package is designed to run reliably on any platform, as container creates its own independent environment.
The difference between containers and virtual machines (VMs) can be illustrated by the following figure:
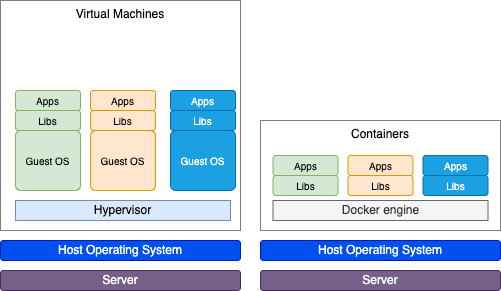
In AWS, containers run on EC2 instances. For example, you might have a large instance and run a few containers on that instance. While running one instance is easy to manage, it lacks high availability and scalability. Most companies and organizations run many containers on many EC2 instances across several Availability Zones. Container orchestration can be done in EKS and/or ECS.
Event-driven architecture¶
Design by thinking: "what are the events that should trigger something in my system". API requests are becoming events, data updates in the DynamoDB are also events, event design allows to build very loosely coupled systems that integrate with other systems.
- Event-driven architectures use events to communicate between services and invoke decoupled services.
- AWS Lambda is a serverless compute service that is well suited to event-driven architectures.
- Lambda has native support for events produced by message and streaming services like Amazon Simple Queue Service (SQS), Amazon Simple Notification Service (SNS), and Amazon Kinesis.
- Adding SQS queue in front of Lambda to create asynch connection between API request and the function processing. API Gateway sends request to Amazon SQS. Lambda service uses long polling to poll the SQS queue.
- By default, Lambda reads up to five batches at a time and sends each batch within one event to our function.
- If a Lambda function returns errors when processing messages, Lambda decreases the number of processes polling the queue.
- When the Lambda function successfully processes a batch, the Lambda service deletes that batch of messages from the queue.
- If any of the messages in the batch fail, all items in the batch become visible on the queue again. Which will generate duplicates.
- When a message continues to fail, send it to a dead-letter queue, another SQS queue.
-
AWS Step Functions can coordinate the distributed components of the application and keep the need for orchestration out of the code.
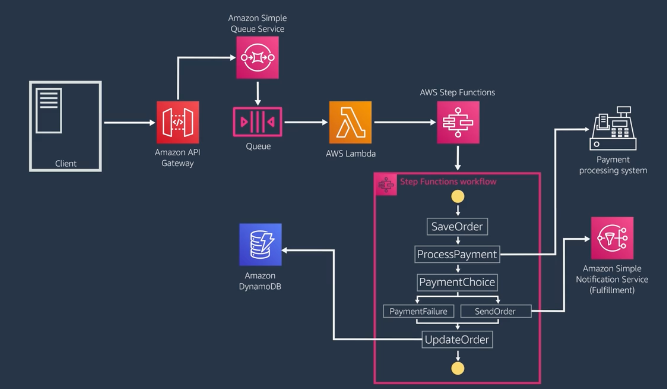
Communicate status updates back to client¶
- At the client side, the client app may poll on a specific
/status/{mid}API with a messageID returned by the SQS queue response, and may use another end point (/order/{id}) to get the transaction result. This approach adds additional latency to the data consistency within the client. - Client may use Webhooks as user-defined HTTP callbacks. The callback is called from a SNS topic subscriber. Using SNS with HTTP subscribers can use retries and exponential backoff until the webhook succeeds. To handle webhook failures, we need a defined process with an agreed-upon expiration time window and number of retries to communicate to the webhook.
- As a 3nd solution is to use WebSocket with GraphQL integrated with
AppSync. This is a bidirectional communication between the API and the client. With AWS AppSync, clients can automatically subscribe and receive status updates as they occur. - Amazon Simple Notification Service (Amazon SNS) uses a publication/subscription. It is possible to define filter policies to topic subscription. The filter policy contains attributes that define which messages that subscriber receives, and Amazon SNS compares message attributes to the filter policy for each subscription.
- Amazon SNS supports a very high number of subscribers per topic, which means we can kick off a large number of processes with one SNS message.
Data processing patterns¶
- Data streams is supported with Kinesis Data Streams, and clients use KCL (consumer), KPL (producer) APIs and AWS SDK to interact with stream. Lambda can be a consumer or producer. Recall that Write is 1000 records/s or 1MB/s and read is 5 tx/s up to 10k records with 2MB/s
- Data processing never happens in isolation. The correct architecture depends on how the data will be used, transformed, and stored.
- Kinesis Data Firehose does not support exactly once delivery and record ordering. When we associate a Lambda function to a Data Firehose stream to transform data on the stream, Data Firehose tries the invocation three times and then skips that batch of records. Records that failed to process are delivered to an Amazon S3 bucket in a
processing_failedfolder. -
Kinesis Data Streams guarantees order delivery of data records in the shard as well as exactly-once delivery of records. If Lambda fails on one record in a batch, the entire batch (and thus the shard) is blocked until either the message processes successfully or the retention period for the data records in the batch expires.
- Data Firehose Dev guide.
- Kinesis Data Analytics: Preprocessing Data Using a Lambda Function.
Error Handling by execution model¶
API Gateway - synch
- Timeout – API Gateway has a 30-second timeout. If the Lambda function hasn't responded to the request within 30 seconds, an error is returned.
- Retries – There are no built-in retries if a function fails to execute.
- Error handling – Generate the SDK from the API stage, and use the backoff and retry mechanisms it provides.
SNS - asynch
- Timeout – Asynchronous event sources do not wait for a response from the function's execution. Requests are handed off to Lambda, where they are queued and invoked by Lambda.
- Retries – Asynchronous event sources have built-in retries. If a failure is returned from a function's execution, Lambda will attempt that invocation two more times for a total of three attempts to execute the function with its event payload. We can use the Retry Attempts configuration to set the retries to 0 or 1 instead. If Lambda is unable to invoke the function (for example, if there is not enough concurrency available and requests are getting throttled), Lambda will continue to try to run the function again for up to 6 hours by default. We can modify this duration with Maximum Event Age.
- Error handling - Use the Lambda destinations OnFailure option to send failures to another destination for processing. Alternatively, move failed messages to a dead-letter queue on the function.
Kinesis Data Streams
- Timeout – When the retention period for a record expires, the record is no longer available to any consumer. (24h). As an event source for Lambda, we can configure Maximum Record Age to tell Lambda to skip processing a data record.
- Retries – By default, Lambda retries a failing batch until the retention period for a record expires. We can configure Maximum Retry Attempts so that our Lambda function will skip retrying a batch of records.
- Error handling - Configure an OnFailure destination on our Lambda function so that when a data record reaches the Maximum Retry Attempts or Maximum Record Age, we can send its metadata, such as shard ID and stream Amazon Resource Name (ARN), to an SQS queue or SNS topic.
SQS Queue
- Timeout – When the visibility timeout expires, messages become visible to other consumers on the queue. Set our visibility timeout to 6 times the timeout we configure for our function.
- Retries – Use the
maxReceiveCounton the queue's policy to limit the number of times Lambda will retry to process a failed execution. - Error handling - Write our functions to delete each message as it is successfully processed. Move failed messages to a dead-letter queue configured on the source SQS queue.
Dead-letter
We may turn on dead-letter queues and create dedicated dead-letter queue resources using Amazon SNS or Amazon SQS for individual Lambda functions that are invoked by asynchronous event source.
Distributed tracing with X-Ray¶
Another important best practice for event-driven, decoupled applications is the use of distributed tracing to give us insight into issues, latency spikes or bottlenecks across our distributed architecture.
X-Ray SDK can be used in any application. Can be enabled in Lambda, API Gateway, SQS, SNS, and used to do lineage and application flow with a visual representation of what’s happening at each service integration point, highlighting successful and failed service calls, and time to execute a service.
When X-Ray is enabled, it gets data from services as segments, and groups them by request into traces.
Instead of sending trace data directly to X-Ray, each client SDK sends JSON segment documents to a daemon process listening for UDP traffic.
We may add annotations to segments in order to group traces to help us identify performance stats on application-specific operations. Annotations are indexed within X-Ray.
Deeper dive¶
- Create serverless workflow
- 10 Things Serverless Architects Should Know
- Create a State Machine that Implements the Saga Pattern
- Error handling and automatic retries in AWS Lambda
- Handle Lambda Errors in API Gateway
- Step function example retry and catch
- AWS Event Fork Pipelines are prebuilt applications, available in the AWS Serverless Application Repository, that we can use in our serverless applications. Each application is packaged with an AWS Serverless Application Model (SAM) template that defines the AWS resources used.
Serverless architecture patterns¶
Few write / Lot of reads app (To Do)¶
The mobile application access application via REST HTTPS through API gateway. This use serverless and users should be able to directly interact with s3 buckets. They first get JWT token to authenticate and the API gateway validates such token. The Gateway delegates to a Lambda function which goes to Dynamo DB.
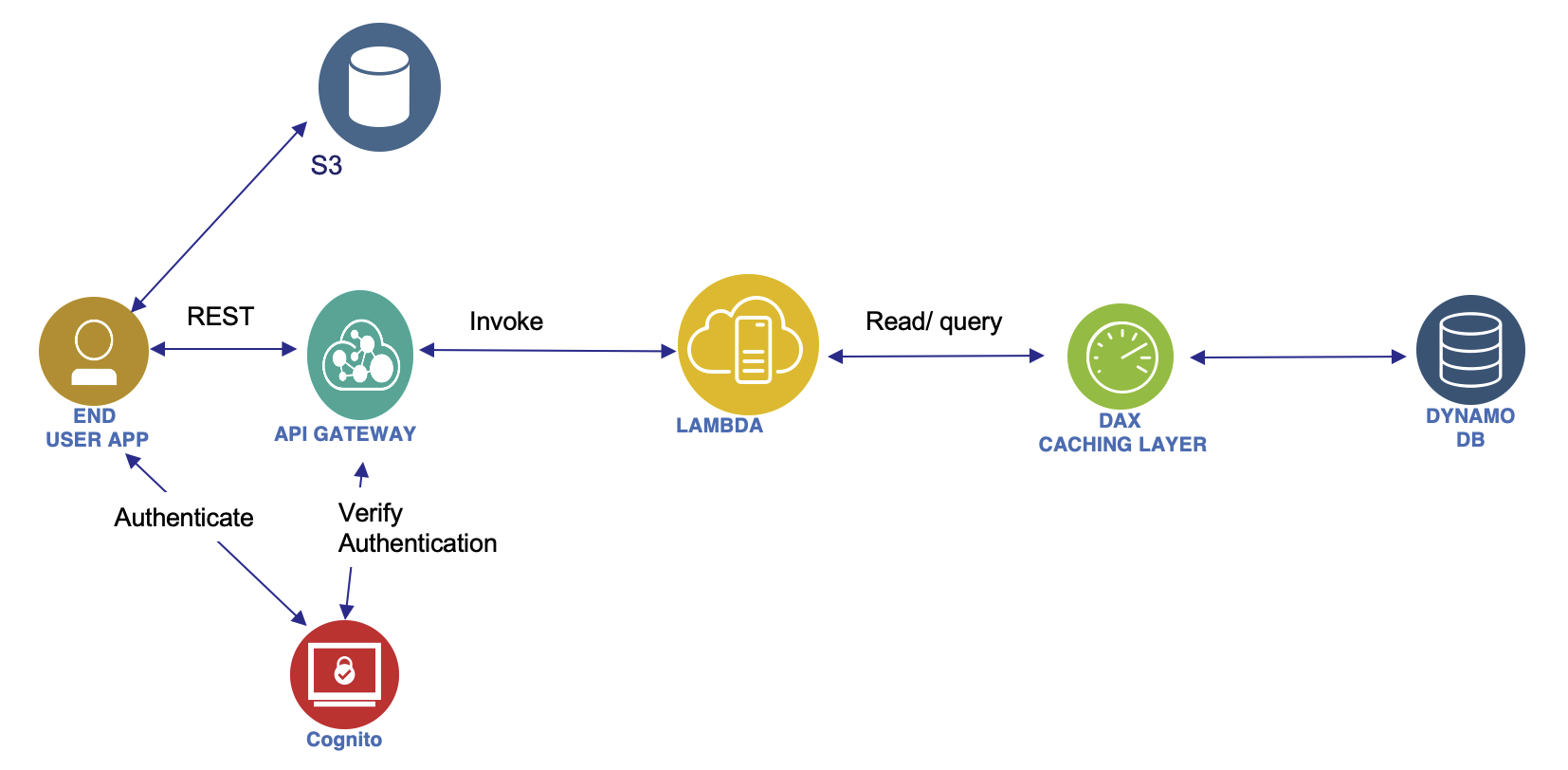
Each of the component supports auto scaling. To improve read throughput cache is used with DAX. Also some of the REST request could be cached in the API gateway. As the application needs to access S3 directly, Cognito generates temporary credentials with STS so the application can authenticate to S3. User's credentials are not saved on the client app. Restricted policy is set to control access to S3 too.
To improve throughput we can add DAX as a caching layer in front of DynamoDB: this will also reduce the sizing for DynamoDB. Some of the responses can also be cached at the API gateway level.
Serverless hosted web site (Blog)¶
The public web site should scale globally, focus to scale on read, pure static files with some writes. To secure access to S3 content, we use Origin Access Identity and Bucket policy to authorize read only from OAI.
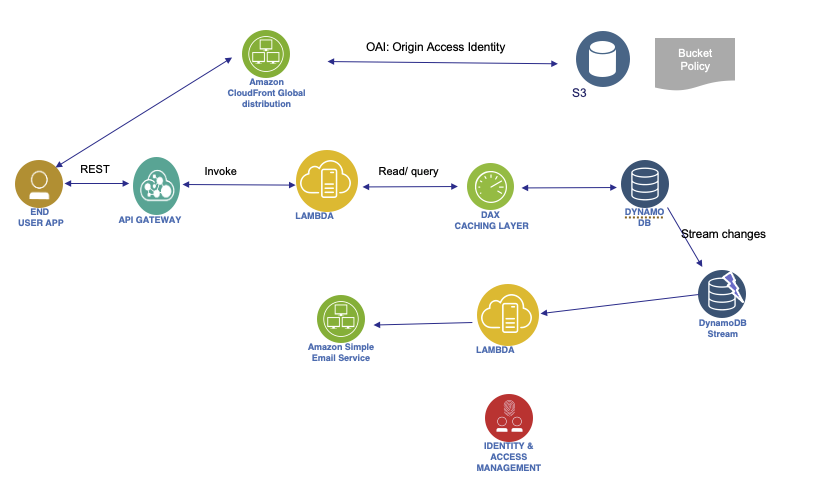
To get a welcome message sent when a user register to the app, we can add dynamoDB streams to get changes to the dynamoDB and then calls a lambda that will send an email with the Simple Email Service.
DynamoDB Global Table can be used to expose data in different regions by using DynamoDB streams.
Microservice¶
Services use REST api to communicate. The service can be dockerized and run with ECS. Integration via REST is done via API gateway and load balancer.

Paid content¶
User has to pay to get content (video). We have a DB for users. This is a Serverless solution. Videos are saved in S3. To serve the video, we use Signed URL. So a lambda will build those URLs.
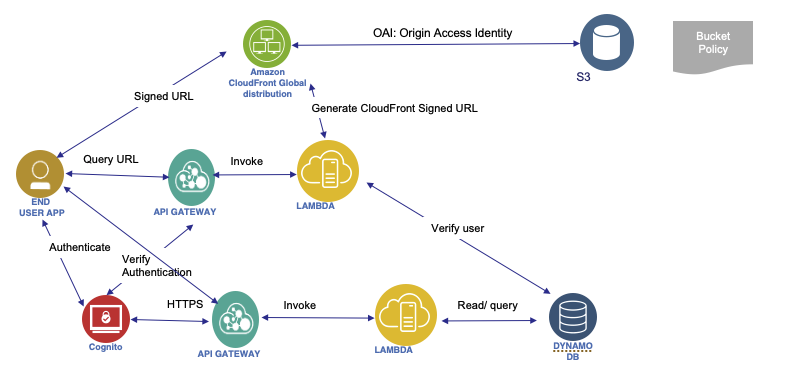
CloudFront is used to access videos globally. OAI for security so users cannot bypass it. We can't use S3 signed URL as they are not efficient for global access.
Big Data pipeline¶
The solution applies the traditional collect, inject, transform and query pattern.

IoT Core allows to collect data from IoT devices. Kinesis is used to get data as streams, and then FireHose upload every minute to S3. A Lambda can already do transformation from FireHose. As new files are added to S3 bucket, it trigger a Lambda to call queries defined in Athena. Athena pull the data and build a report published to another S3 bucket that will be used by QuickSight to visualize the data.
Designing for Serverless¶
Some of the common design patterns to consider when migrating to serverless:
- Leapfrog: bypass interim steps and go straight from an on-premises legacy architecture to a serverless cloud architecture.
- Organic: lift and shift. Experiment with Lambda in low-risk internal scenarios such as log processing or cron jobs.
- Strangler: incrementally and systematically decomposes monolithic applications by creating APIs and building event-driven components that gradually replace components of the legacy application. New feature branches can be serverless first, and legacy components can be decommissioned as they are replaced.
Good questions to assess¶
| Question | Comment |
|---|---|
| What does the application do and how are its components organized? | Establish a bounded context for each microservice. Assess entity and data store. |
| How can you break your data needs based on the command query responsibility segregation (CQRS) pattern? | Strangle data by needs. Decouple write transaction from queries at scale. |
| How does the application scale and what components drive the capacity you need? | Look at independent scaling, and high scaling demand. |
| Do you have schedule-based tasks? | cron jobs are good targets to replace with Lambda functions |
| Do you have workers listening to a queue? | Decoupling may already being adopted, EDA discussions may be started. |
| Where can you refactor or enhance functionality without impacting the current implementation? | Look at API needs, ALB needs. |
See Serverless app Lens in AWS Well Architected.
Scaling¶
While considering ways to scale a serverless architecture, there are some best practices to consider:
- Separate the application and database.
- Take advantage of the AWS Global Cloud Infrastructure.
- Identify and avoid heavy lifting.
- Monitor for percentile.
- Refactor as we go.
We need to know the capabilities and service limits of the services that we’re integrating. Considering assessing timeouts, retry behaviors, throughput, payload size.
For example with API Gateway, there are configuration options for each API, that can help to improve access like with edge-optimized endpoint, using CloudFront distribution. Or use cache to avoid reaching backend.
Consider looking after the following questions:
- Who will be using each API?
- Where will they be accessing it from, and how frequently?
- What are the downstream systems that could impact performance?
- Do you need to throttle requests at the "front door" to prevent overloading a downstream component?
Info
For Lambda, lambda authorizer lets us implement a custom authentication scheme, that uses either request parameters to determine the caller's identity, or bearer token authentication. We need to anticipate the volume of authorization requests to ensure we don’t exceed our concurrency limits. We can use auth caching to mitigate this.
When Amazon SQS is used as a Lambda event source, the Lambda service manages polling the queue. We can set the batch size, concurrency limit, and timeout. Lambda defaults to using five parallel processes to get messages off a queue. If the Lambda service detects an increase in queue size, it will automatically increase how many batches it gets from the queue, each time. The maximum concurrency is 1000.
SQS will continue to try a failed message up to the maximum receive count specified in the re-drive policy, at which point, if a dead-letter queue is configured, the failed message will be put into the dead-letter queue and deleted from your SQS queue.
If the visibility timeout expires, before your Lambda function has processed the messages in that batch, any message in that batch that hasn’t been deleted by your function will become visible again. This may generate duplicate processing on the same message. The best practice, is to set your visibility timeout to six times the function timeout.
A concurrency limit that is set too low could definitely cause an increase in messages hitting the dead-letter queue. Anything less than five will generate errors out of the gate because Lambda defaults to five processes pulling batches off the queue and invoking functions.
- See using lambda with SQS
- Configure SQS queue to trigger lambda
- Tutorial SQS / Lambda, KMS key to encrypt message, using Dead Letter Queue.
Security¶
One benefit of serverless architectures is that when we rely on AWS managed services, we shift more parts of the AWS shared responsibility model toward AWS. Our responsibility includes: Follow the principle of least privilege; protect data at rest and in transit; and audit the system for changes, unexpected access, unusual patterns, or errors.
- Best Practices for Security, Identity, & Compliance
- OWASP Secure Coding Practices Quick Reference Guide
Here is a classical story of a customer use case where security context is in each components and networking between those elements:
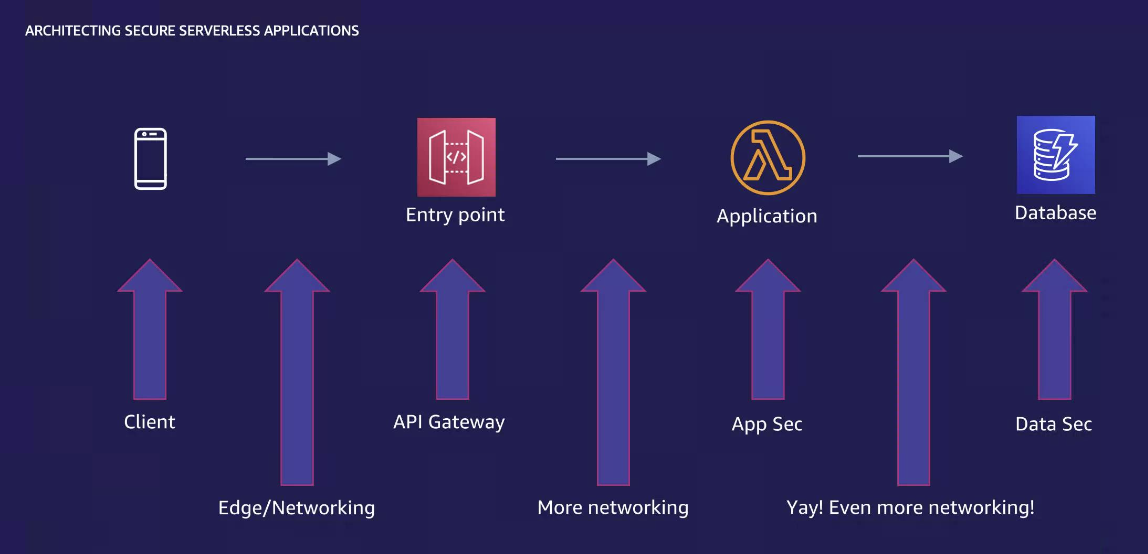
Amazon API Gateway is the front door to your application, so start preventing unauthorized access to our APIs. There are three options for authorization*:
- AWS Identity and Access Management: for client in AWS
- Amazon Cognito: supports sign-in/sign-up capabilities or acts as an identity provider (IdP) in a federated identity scenario.
- Lambda authorizers: An API Gateway Lambda authorizer invokes a Lambda function to authenticate/validate a user against your existing IdP.

WAF offers capabilities to avoid SQL injection, OWASP top 10, XSS rules.
Using IAM policies and roles to define who can invoke the Lambda function, and what services the function can reach. Don’t share IAM roles between functions.
To pass data to a Lambda function we can use environment variable, AWS Systems Manager Parameter Store, AWS secret manager. Secrets Manager has the added benefit of secrets rotation and cross-account access.
Think about security end to end at each integration point in the distributed architecture. Here is a deeper dive from re:inforce 2019 about Securing Serverless app with security patterns to consider, like authentication, defense from external threat, control application access with IAM policies, lambda execution role...
Observability¶
Defintion: A measure of how well internal states of a system can be inferred from knowledge of that systems's external outputs.
Understand what is happening in our systems and applications to detect, investigate, and remediate problems.
The goal is to be able to answer:
- Which decoupled service is up or down?
- Which service is causing a performance bottleneck?
- Slow application, service?
- How KPI or SLA are still being met?
To achieve insight, use the three different pillars of observability: Metrics/ monitoring, trace and logs. (See CloudWatch metrics, Amazon CloudWatch Logs, and AWX X-Ray for end to end tracing).
Lambda built-in metrics include total invocations, errors, duration, throttles, dead-letter queue errors, and iterator age, which helps troubleshoot stream-based invocations.
- Amazon API Gateway dimensions and metrics
- Working with Lambda function metrics
- Available CloudWatch metrics for Amazon SQS
- Monitoring Step Functions Using CloudWatch
- Monitoring Amazon SNS topics using CloudWatch
- Monitoring the Amazon Kinesis Data Streams Service with Amazon CloudWatch
Auditing¶
Audit the configuration history, configuration changes, and all other API calls to facilitate security and governance in the serverless applications.
Use Cloud Trail to record API usage, so we can assess who modify the resources. Automatically enabled at account creation. A trail is a configuration that enables the delivery of CloudTrail events to an Amazon Simple Storage Service (Amazon S3) bucket, Amazon CloudWatch Logs, and Amazon CloudWatch Events. If you need to maintain a longer history of events, you can create your own trai
Use AWS Config to track changes to the application, that can track activities on some AWS services. We can define rules to enforce compliance. AWS Config flags the resource and the rule as noncompliant and notifies you through Amazon Simple Notification Service (Amazon SNS).
GraphQL vs RESTful APIs¶
- GraphQL Foundation 2018: Support single static path and POST request.
-
The query is in the body as a json document.
query getAllCars(zip) { getAllCars(zip){ carid model capacity location } } -
AppSync supports GraphQL and uses resolver to retrieve fields from data sources and mapping to schema.
- Consider development experience: RESTful is supported by all browsers, a lof of HTTP client code, widely accepted standard. GraphSQL uses SDK, and is less common adopted.
- With a lot of datasources, which may change often, GraphQL may be a good fit.
- When we do not control the client then REST is a better choice.
| Benefits | REST | GraphQL |
|---|---|---|
| Data Size | Defined by server and schema | Can change based on data requested by client |
| Payload shape | Static schema defined by server | Defined by what client ask for |
| Client support | Works with browsers | Requires JS libraries |
Fargate¶
When running ECS and EKS on EC2, we are still responsible for maintaining the underlying EC2 instances. With Fargate, we do not have to manage EC2 instances.
AWS Fargate is a purpose-built serverless compute engine for containers. Fargate scales and manages the infrastructure, it removes the need to provision and manage servers, let you specify and pay for resources per application, and improves security through application isolation by design.
It natively integrates with AWS Identity and Access Management (IAM) and Amazon Virtual Private Cloud (VPC).
It uses the following constructs:
- Task Definition: to define application containers, image URL, CPU and memory needed... It is immutable, so any update creates new version. It can define 1 to 10 container definitions. The container definition part includes memory reservation and cpu allocation.
- Task: A running instance of a Task Definition. A task can have multiple containers running in parallel. Each task has its own Elastic Network Interface with a private IP @ from the subnet.
- Cluster: infrastructure isolation boundary. Tasks run in the cluster.
- Service: Endpoint to support ELB integration and do mapping to tasks
Pricing is based on what we provision, then the task level CPU and memory and the per-second billing with one minute minimum.
To share data between containers, Fargate provides 4 GB volumes space per task, and the volume is mounted in the container. By default, Fargate tasks are given a minimum of 20 GiB of free ephemeral storage.
For IAM security, the same policies can be set as we do for EC2. We still need to add an execution role to define access to ECR to download images and CloudWatch for monitoring.
Examples¶
- ECS nginx demo in ECS playground
- Deploy Flask App from private ECR repository with AWS Console
- Deploy Flask App with CDK
Step Function¶
See separate note.
AWS App runner¶
AWS App Runner, a fully managed container application service that makes it easy for customers without any prior containers or infrastructure experience to build, deploy, and run containerized web applications and APIs
Amazon Lightsail¶
Lightsail is a VPS provider and is a useful way to get started with AWS for users who need a solution to build and host their applications on AWS Cloud. Lightsail provides developers with compute, storage, and networking capacity and capabilities to deploy and manage websites and web applications in the cloud. Lightsail includes VMs, containers, databases, content delivery network (CDN), load balancers, Domain Name System (DNS) management,
Read more¶
- 10 Things Serverless Architects Should Know
- Serverless Land - AWS portal on Serverless
- Build on serverless - season 2 - 2020
- 2021 re:Invent playlist for serverless breakout sessions
- Technical talks
- AWS serverless getting started - official page
- Getting started with serverless - For developer. Create a lambda, API gateway to send message from GitHub to Slack. https://hooks.slack.com/services/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
- Live coding well-architected solution - 2020
- Serverless patterns collection: a portal to access SAM template and code or AWS CDK.
- Implementing Safe Lambda Deployments with CodeDeploy
- API patterns Restful vs GraphQL APIs - George Mao 2020.
Workshops¶
-
Serverless patterns - immersion days done in cloud 9 Development machine and serverless-immersion-day folder.
- Module 1: API Gateway - Lambda - DynamoDB
- Module 2: Cognito, Lambda authorizer, API Gateway, Lambda (CRUD), DynamoDB + SAM. Sam template in labs/serverless/ws-serverless-patterns folder
- Module 3: CI/CD
- Assessment: 5 :octicons-star-fill-24:{ .star } but too much of mixing lambda = serverless.
-
Build, Secure, Manage Serverless Applications at Scale on AWS
-
Decoupled microservice workshop
- Lab 1 - Fan-out & message filtering: use SNS to get multiple services (lambda fcts) to subscribe to the topic, API Gtw exposes API to a Lambda which persist data in DynamoDB and send to SNS. The function is not idempotent, and not transactional. See labs/serverless/asynchronous-messaging/fanout-sns
- Lab 2 - Topic-queue chaining & load balancing: in previous example, it is possible subscriber service may miss topic messages. See labs/serverless/asynchronous-messaging/topic-queue-chaining
- Lab 3 - scatter pattern by sending messages through multiple channels. The application comprises of API Gateway endpoints and lambda functions which provide the ability to send requests for quote and to query the responses. Service providers have subscribed to a SNS topic which is used to publish the request for quote (RFQ). On receiving the RFQ message, service providers send their response for quotes in a queue. The queue triggers a lambda function which loads the responses in a DynamoDB table. The response for quotes service queries all the responses based on request id. See labs/serverless/asynchronous-messaging/scatter-gather
- Lab 4 - Orchestration and coordination: to demonstrate how to support long lived transaction across distributed components using Step function to ensure data consistency across microservices. See labs/serverless/asynchronous-messaging/orchestration
- Serverless Observability Workshop
-
Building event-driven architectures on AWS: it uses nested cloud formation templates reproduced in the
labs/edafolder. it uses Amazon EventBridge, Cognito, Amazon SNS, Amazon SQS, AWS Lambda, Step functions...