Databricks¶
Databricks helps organizations make their data ready for analytics, empowering data science teams to make data-driven decisions and rapidly adopt machine learning via there proprietary platform Data Lakehouse. The current Data Lakehouse platform tenets revolve around:
- Multi-tenant control plane ( 1 or more per region)
- Single-tenant data plane in Customers account
- Databricks workspace provides an interactive environment where users can collaborate, develop, and deploy data-driven applications. It offers a unified interface, supports multiple programming languages, and provides built-in libraries and frameworks. With features like version control, job scheduling, and integration with other tools and services.
- Each workspace maps to one VPC (one region)
- Multiple workspace maps to one VPC
- Cross account IAM roles used to launch and manage the clusters
- Clusters are used to connect to different data stores like Databases, streaming, on-prem, private hosted Github/code repos...
Based on Apache Sparks, Delta Lake, and MLflow, with HDFS,. Once deployed on AWS, it uses resources like EC2, EKS, S3, IAM, EBS volumes...
Workspace manages assets for a user:

- Repos is to support integration with Git compatible repositories and clone locally in the workspace.
- Clusters to define different cluster run time to run notebooks or jobs.
- Secrets to keep keys and other sensitive information.
- Pipelines for data processing pipelines.
- Pools keeps idle VMs.
Value propositions¶
Data warehouse solutions were developed to address data silos done by using multiple, decentralized operational databases. The goal was to provide an architectural model for the flow of data from operational systems to decision support environments. Data warehouse has limitations to support big data, unstructured data, and to support ML use cases. Most of the time uses proprietary formats.
Data lake, with Hadoop, was aiming to support big data processing, on parallel servers organized in cluster. Shortly after the introduction of Hadoop, Apache Spark was introduced. Spark was the first unified analytics engine that facilitated large scale data processing, SQL analytics, and AI Model Learning.
Data lakes are difficult to set up, do not support transactions, do not enforce data quality, very difficult to mix append and read operations, batch and streaming jobs. We can add that modifying existing data is difficult, like a delete operation in the context of GDPR compliance. With data lakes, it is difficult to manage large metadata, and data catalogs. A lot of data lake projects became data swamp.
A lakehouse is a new architecture that combines the best elements of data lakes and data warehouses. It enables users to do everything from BI, SQL analytics, data science, and ML on a single platform. It supports ACID transactions, large metadata, indexing, bloom filters, schema validation, governance to understand how data is used, direct access to source data, scalable. Data is saved in open data formats and supports structured and unstructured data.

Figure 1: Data lake - data pipeline
The lakehouse, with Delta Lake, approach to data pipelines offers modern data engineering best practices for improved productivity, system stability, and data reliability, including streaming data to enable reliable real-time analytics.
Big data and AI complexity slows innovation: managing big data infrastructure, define data pipelines to produce stale data with poor performance, isolated, without any collaboration between data scientists and data engineers.
Delta lake¶
Delta lake is an open approach to bring data management and governance on top of data lakes. It is a storage layer which offers the following characteristics:
- reliability via ACID transaction.
- performance via indexing to maximize the efficiency of the query.
- governance using Unity Catalog to enforce access control list on table.
- quality to support different business needs.
Data Scientists can define flows and pipelines to process data from raw to filtered-cleaned-augmented, as a source of truth to business level aggregates.
The persistence format of data on cloud object stores is Apache Parquet. Delta Lake persists transaction logs in the same folder as data, and it is easy, with Delta API, to get the state of the data inside parquet, for merge-on-read operation. The protocol supports addressing data in file.
Delta Lake is available with multiple AWS services, such as AWS Glue Spark jobs, Amazon EMR, Amazon Athena, and Amazon Redshift Spectrum.
Deeper Dive¶
- Delta Lake documentation
- Crawl Delta Lake tables using AWS Glue crawlers
- Introducing native Delta Lake table support with AWS Glue crawlers
- Process Apache Hudi, Delta Lake, Apache Iceberg datasets at scale, part 1: AWS Glue Studio Notebook
Architecture¶
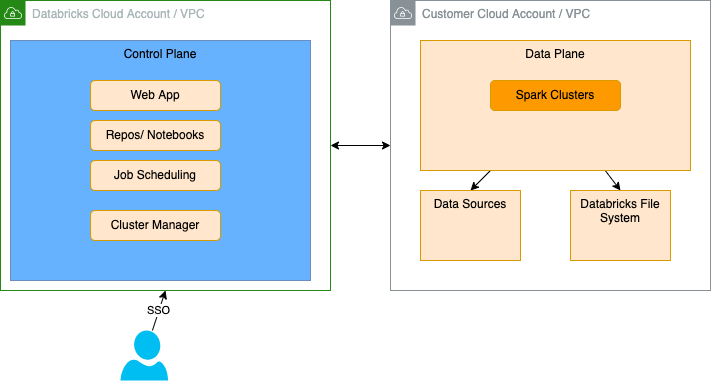
(src: Databricks)
- Control plane is managed by Databricks in their cloud account, and it includes backend services, webapp for workspaces, notebooks repository, job manager, cluster manager... It hosts everything except the Sparks Cluster.
- Each customer has his own workspace, any command runs in workspace will exist inside the control plane.
- Data plane is managed within the customer's cloud account. Data is own, isolated and secured by each customer. Data sources can be inside the customer account or as external services.
- There is a private network between the data and the control planes. A lot of control over how cloud accounts are integrated and secured.
The Webapp is where customers access all the platform interfaces (APIs and UI):
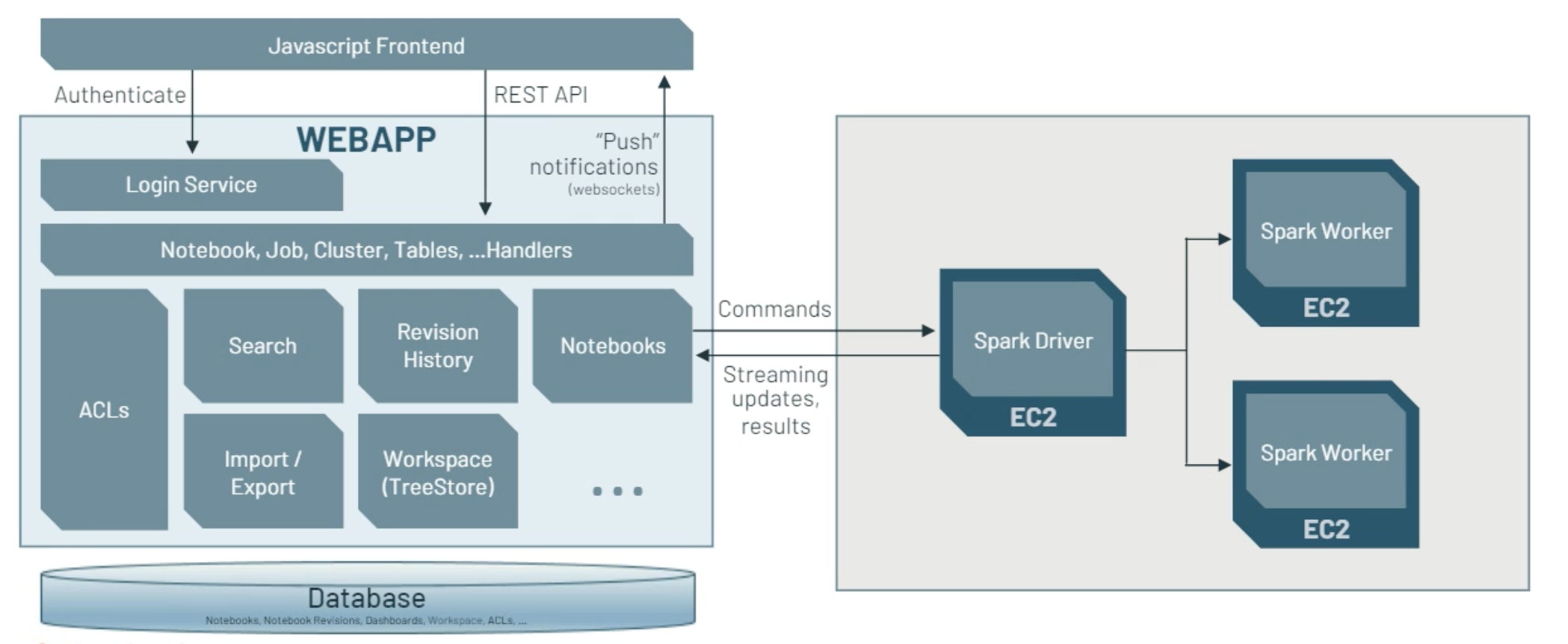
(src: Databricks copyright)
On AWS, the database is RDS and stores all the information about customers metadata, and workspace.
Cluster manager is part of the control plane and helps admin to manage Spark Cluster. The Cluster manager is an extension of the Spark CM with nicer user interface.
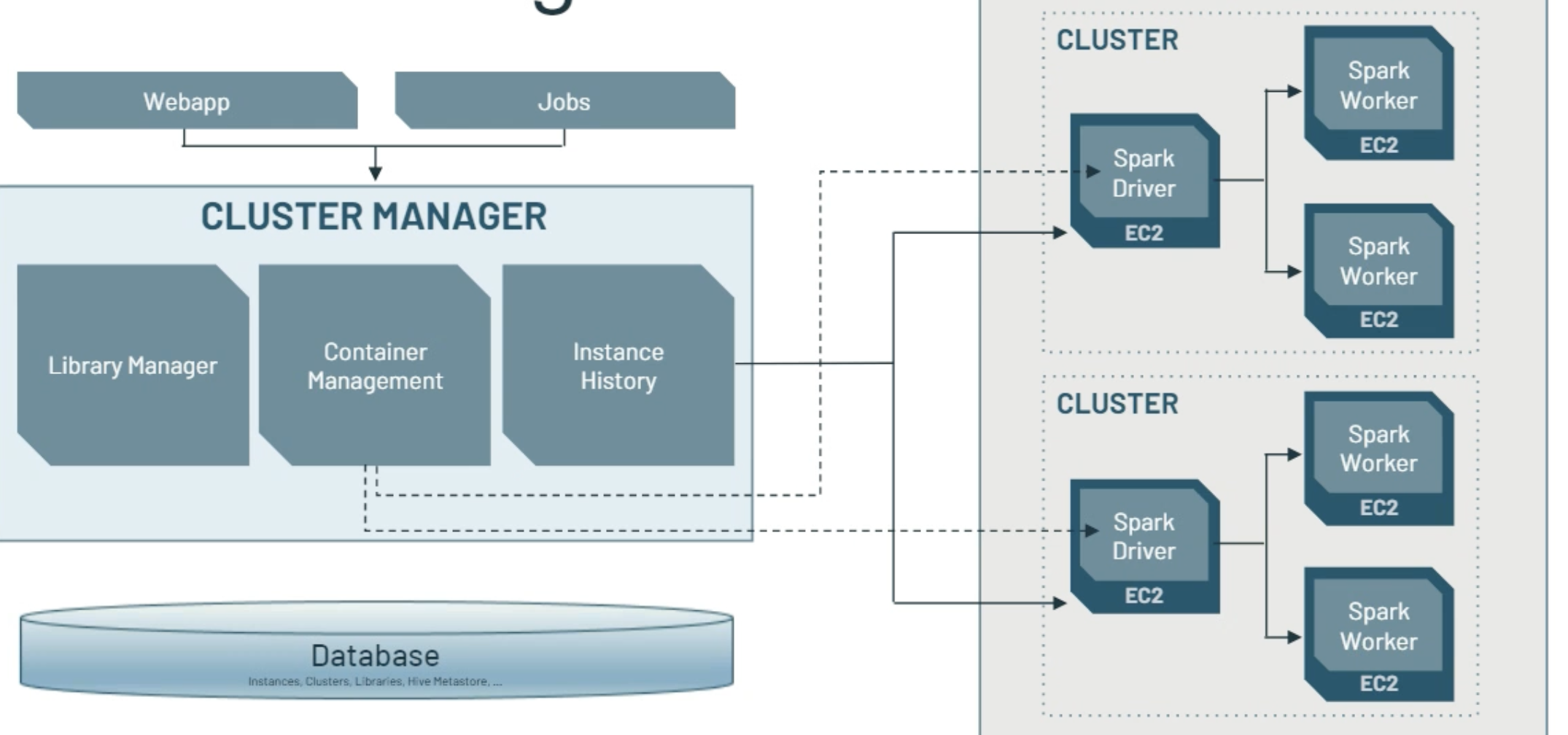
(src: Databricks copyright)
There are two types of cluster: 1/ All-purpose to be used to support interactive notebooks execution, 2/ Job clusters to run automated jobs.
Workspace is a group of folders and files which are mostly notebooks.
An admin end user once connected to the platform can do at least the following tasks:
- Manage users, groups, entitlements, instance profiles (which is is associate to a IAM role pass through attached to the EC2 instances supporting the cluster) .
- Create workspaces and defined access control.
- Manage all-purpose or job clusters.
- Define policy to control resources of the cluster: for example cluster mode specifies the level of isolation, runtime version, ML runtime with GPU access or not... It is possible to specify on-demand and spot instance composition for the number of node in the cluster.
- Submit job. It can also create a cluster to support the job, and then release the resources.
- Create data tables.
- Define MLflow: An open source platform for the machine learning lifecycle.
Two types of compute resource:
- All purpose compute: shared cluster, ad-hoc work, multi tenant, more expensive.
- Job compute: single user, ephemeral clusters created for a job. Great isolation. Lower cost.
Unity Catalog¶
The Unity Catalog offers a fine-grained governance for data lakes across cloud providers and is based on ANSI SQL. It provides a centrally shared (via delta sharing protocol), auditable (what is used, who used, data lineage), secured, management capability for all data types (tables, files, columns and ML models ). It integrates with existing data catalogs and storages.
Databricks SQL¶
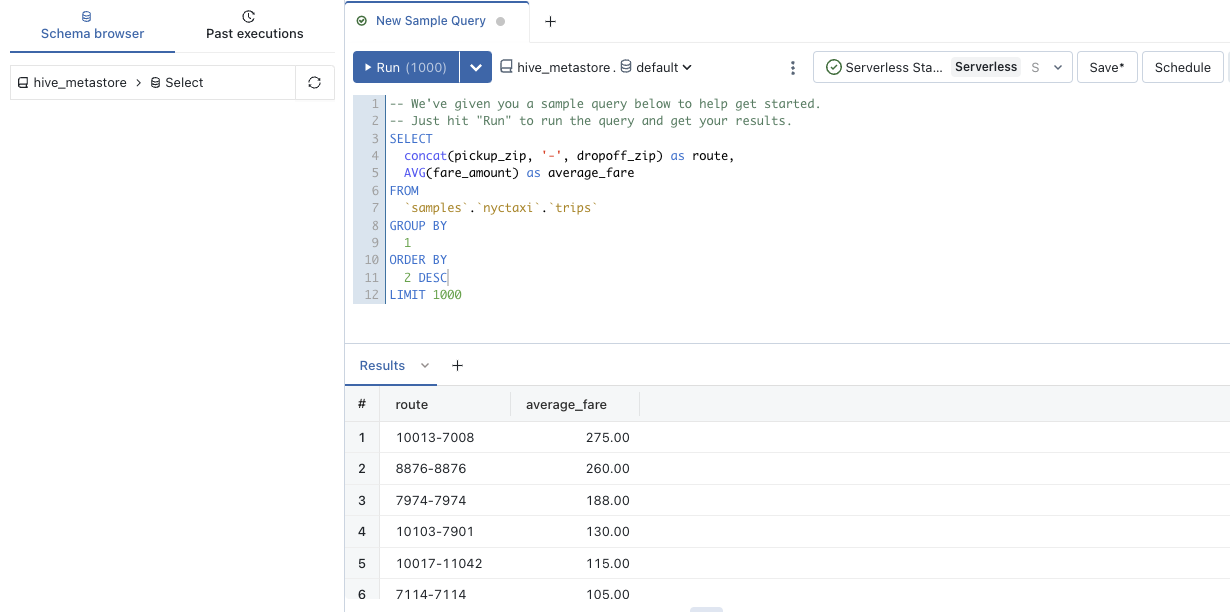
Run SQL queries through SQL optimized clusters, powered by Photon, that directly queries Delta Lake tables.
Note
Photon is a vectorized query engine to take advantages of the new CPUs architecture for extremely fast parallel processing.
The query editor is also integrated with visualization to present the data with diagrams and charts and build dashboards.
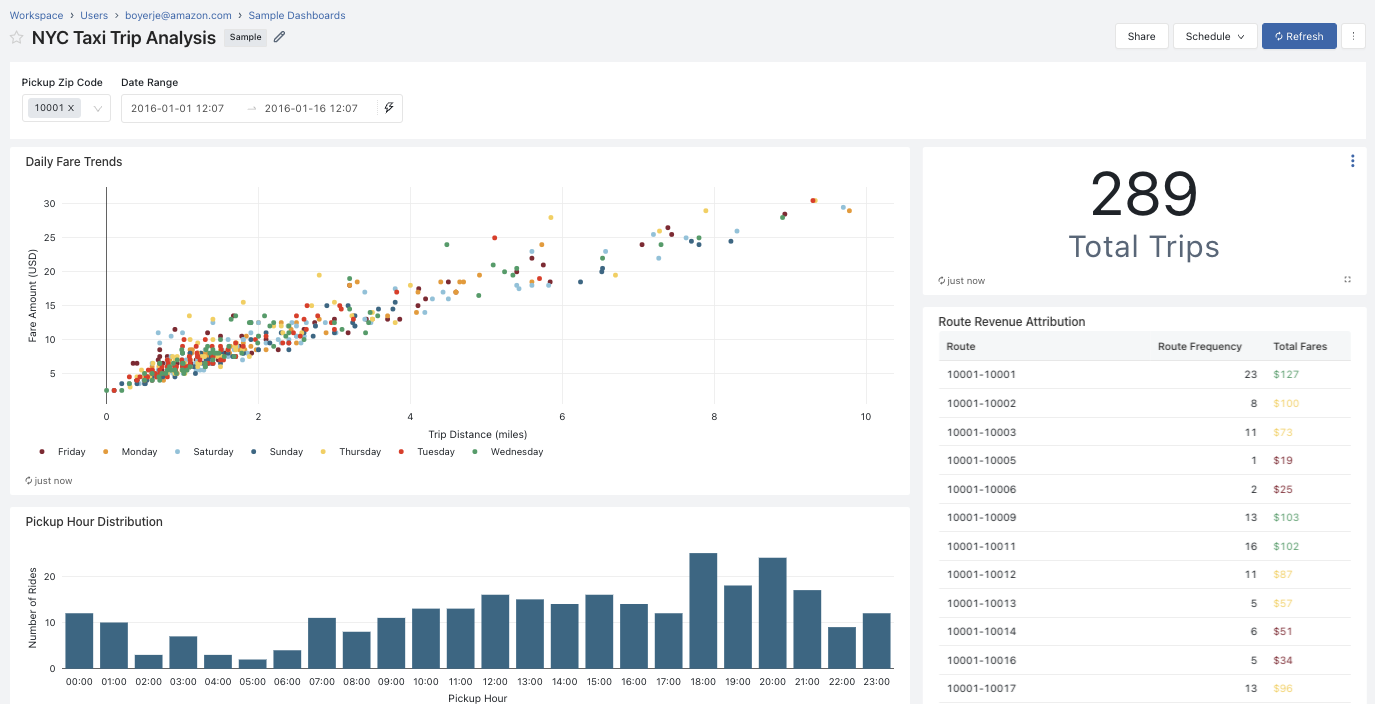
The SQL can be integrated with existing BI tools like Qlik, Tableau, DBT, Fivetran...
To be able to execute SQL, workspace admin user needs to define an endpoint, a Catalog and a database. Serverless endpoints are managed by Databricks, or classical with remote access to data plane to customer's account.
Catalog (samples) is needed to access Databases (nyctaxi):
Support all the management at the query level, looking at execution history, and fine-grained access control.
SQL warehouse supports 3 types:
- Classic as entry level
- Pro
- Serverless: SQL warehouses run in the customer’s Databricks account using serverless compute.

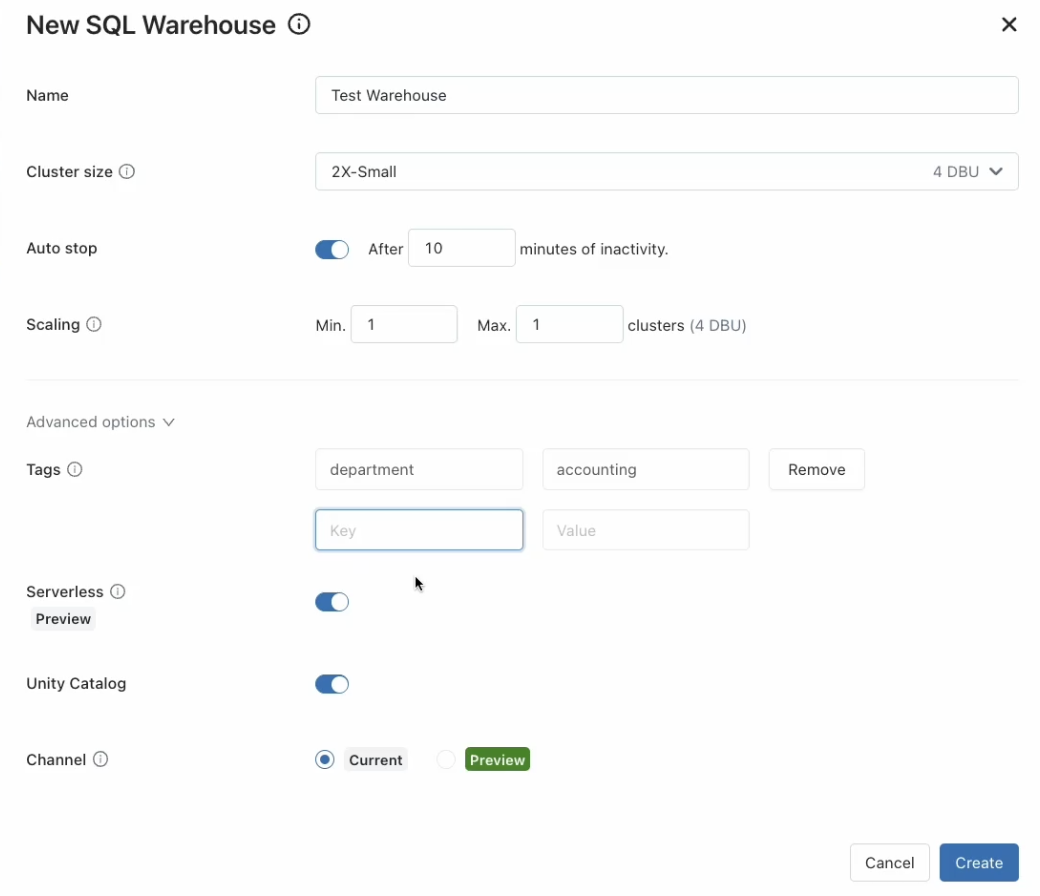
Creating a Warehouse helps to configure the cluster size and type, scaling characteristics (which lead to different pricing in DBU units), and the catalog:
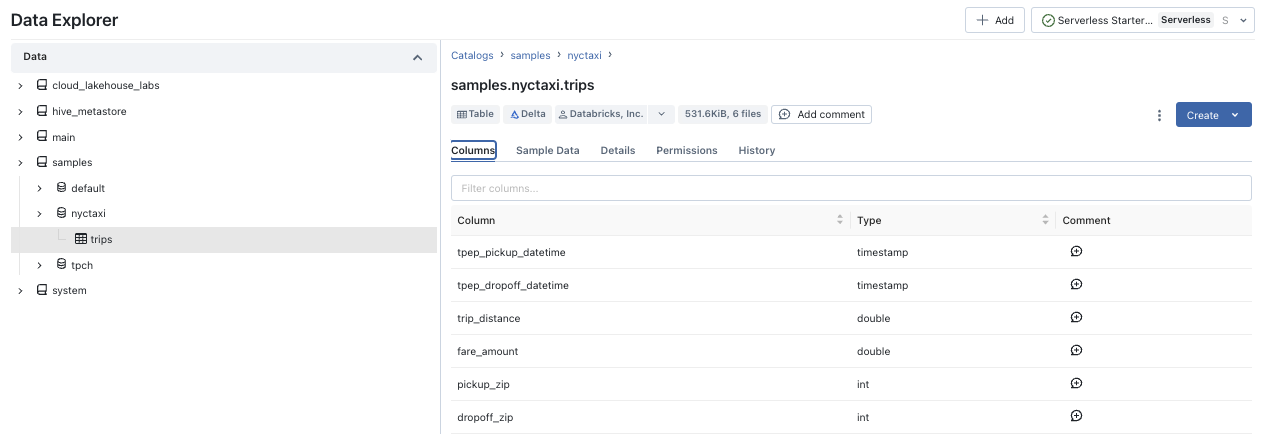
Within a catalog, we can use Data Explorer to see the database, the tables (trips) and then the column declarations:
Using query we can define Alert.
Machine Learning¶
The libraries used are TensorFlow, XGBoost, Scikit-learn, pyTorch.
The ML service uses MLFlow which includes the following components:
- Models: manage and deploy models from a variety of ML libraries to a variety of model serving and inference platforms.
- Projects: package ML code in a reusable, reproductible form to share.
- Model registry
- Model serving
- Feature serving, serves pre-computed features as well as compute on-demand features using a single REST API in real time (within milliseconds latency) for any AI applications.
Feature Serving¶
Serverless capability to serve pre-computed features as well as compute on-demand features using a single REST API.
As ML usage increases across industries, the sophistication of ML pipelines is also increasing, with many customers moving from batch to real-time predictions. For real-time models to have the greatest business value, they need to be sensitive to the latest actions of the user. Feature engineering is at the core of modeling complex systems, with features being data signals used as inputs to ML models.
When computing features from raw data, tradeoffs must be made regarding complexity, data size, freshness requirements, latency, cost and importance to predictions.
Data freshness measures the time from a new event to the feature value being updated or available for inference.
Architectures for computing features can be batch, streaming, or on-demand, with varying complexity and costs.
- Batch computation frameworks like Spark are efficient for slowly changing features (hours to days) or those requiring complex calculations on large data volumes. With batch, pipelines pre-compute features and materialize them in offline tables for low latency access by real-time models.
- On-demand computation computes features from latest signals at scoring time, suitable for simpler calculations on smaller data. On-demand is also suitable when features change value more frequently than being used in scoring. Examples of features best computed on-demand include user product viewing history and percentage of discounted items in a session.
- Streaming continuously pre-computes feature values on data (for data where data freshness is within minutes) streams asynchronously, for features requiring larger computation or higher data throughput than on-demand.
How to choose the best architecture?
The starting point for selecting a computation architecture is the data freshness and latency requirements. For less strict requirements, batch or streaming are first choices as they are simpler and can accommodate large computations and deliver predictable latency. For models that need to react quickly to user behavior or events, data freshness requirements are stricter and on-demand architecture is more appropriate. Use spark structured streaming to stream the computation to offline store and online store. Use on-demand computation with MLflow pyfunc. Use Databricks Serverless realtime inference to perform low-latency predictions on your model.
To avoid skew between online and offline computation of on-demand features, it is recommended to yse MLflow pyfunc to wrap model training/prediction with custom preprocessing logic, which helps reusing the same featurization code for both model training and prediction. Features are generated the same way both offline and online.
Travel recommendation example notebook on AWS.
Sources¶
Serverless deployment¶
The serverless deployment is running Databricks control plane as pods in EKS, and customers can run their Sparks job (SQL processing as of now), in nodes added dynamically inside EKS cluster. For security reason the Spark job manager runs in VM (k8s sandboxing pattern) to provide better isolation.
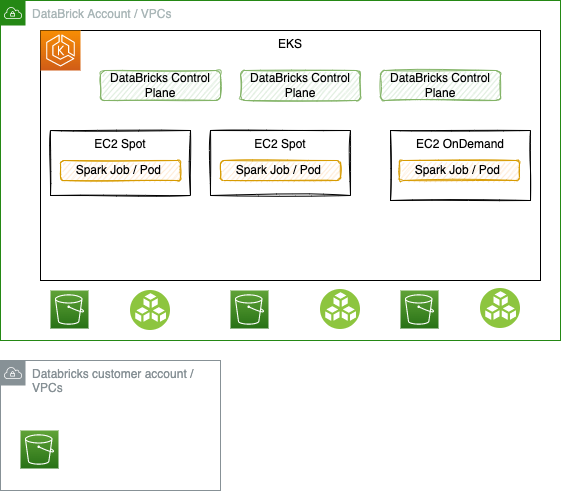
The goal is to support different node types: spot instance, or dedicated VM or even microVM on EC2 baremetal. In the serverless world it is possible to have thousand of VMs / nodes in kubernetes cluster and hundred of start/stop events per second.
Each job processing is done on data that will most likely come from S3 buckets within Databricks account, in the same region, or copied from customer's S3 buckets to EBS volumes attached to the EC2. There are still some use cases where data will stay in S3 bucket of a customer's AWS account, while compute run on EKS clusters of Databricks.
For real-time processing, Spark streaming may be used, connected to Kafka, Kinesis, and any queueing systems. Java or Scala based processing will take longer time to start than SQL based deployment.
Hands on enablement¶
See my Apache Sparks study and ML study.
-
Example of python to read csv file and save it in Delta Lake format
from pyspark.sql.functions import avg diamonds = spark.read.csv("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header="true", inferSchema="true") diamonds.write.format("delta").mode("overwrite").save("/delta/diamonds") display(diamonds.select("color","price").groupBy("color").agg(avg("price")).sort("color")) -
Then read it using SQL
- Cloud Lakehouse labs Github
- Data engineering learning path - Github