Local code and demonstrations, plus other public references¶
This section lists the current demonstrations and labs in this git repository or the interesting public repositories about Flink
1. Flink SQL¶
Under code/flink-sql folder
1.1 Basic SQL & Getting Started¶
| Sample | Path | Description |
|---|---|---|
| Basic SQL (employees, dedup, aggregation) | flink-sql/00-basic-sql | CSV employees demo: create table, deduplication (ROW_NUMBER), aggregation by department, streaming vs batch. Confluent Cloud: customers table, dedup, tombstone creation, snapshot query. Terraform in cc-flink/terraform/. |
| OSS / local Flink | flink-sql/00-basic-sql/oss-flink | create_customers.sql, create_orders.sql for local Flink. |
1.2 Kafka & Connectors¶
| Sample | Path | Description |
|---|---|---|
| Kafka + Flink (Docker, local, Confluent) | flink-sql/01-kafka-flink | Docker Compose (Kafka + Flink 1.20), word count from Kafka topic (user_msgs → word_count), SPLIT + UNNEST. Local Kafka + Flink binary, Confluent Cloud Kafka (TO DO). Optional Datagen connector configs in datagen-config/. |
| Kafka-Flink Docker | flink-sql/01-kafka-flink/kafka-flink-docker | docker-compose.yaml, Kafka config, Flink Kafka connector JARs, starting_script.sql. |
1.3 Nested Rows, Arrays & JSON¶
| Sample | Path | Description |
|---|---|---|
| Nested ROW, ARRAY_AGG, UNNEST | flink-sql/03-nested-row | Nested user schema (vw.nested_user.sql, dml.nested_user.sql), ARRAY_AGG with tumbling window (vw.array_of_rows.sql), CROSS JOIN UNNEST. Sample fligh_out.json. |
| Truck loads (last record per key from array) | flink-sql/03-nested-row/truck_loads | Source with ARRAY<ROW>, UNNEST, upsert sink to keep last load per truck. DDL, DML, insert data. |
| Suite / asset ARRAY_AGG | flink-sql/03-nested-row/cc-array-agg | Aggregate asset IDs per suite with changelog (upsert). cc_array_agg.sql, cc_array_agg_on_row.sql. |
| Healthcare CDC transformation | flink-sql/03-nested-row/cc-flink-health | CDC JSON → flattened Member/Provider entities. Schemas, Flink SQL transforms, Python producer, Schema Registry, test data. |
1.4 Joins¶
| Sample | Path | Description |
|---|---|---|
| Joins playground (overview) | flink-sql/04-joins | Stream-stream joins (orders, products, shipments): left join, CTAS upsert, interval join. Order-per-minute windowing, UNNEST product_ids, avg volume per minute. Data skew (salted joins). docker-compose.yaml. |
| CC stream-to-stream (orders, products, shipments) | flink-sql/04-joins/cc | DDLs and inserts for orders, products, shipments; order–product join, CTAS joins; avg product volume per minute. |
| Inner join with dedup (Asset / AssetType) | flink-sql/04-joins/cc_inner_join_with_dedup | Entity–entityType: ROW_NUMBER dedup on raw assets and types, inner join, ARRAY_AGG for subtype/type names. Confluent Cloud. |
| Data skew (salted joins) | flink-sql/04-joins/data_skew | Join user–group with optional salting to handle skew. DML and insert scripts. |
| Event status processing | flink-sql/04-joins/event_status_processing | CDC-style event_status (eventId, eventProcessed, eventTime). DDL and processing pattern. |
| Group / user hierarchy | flink-sql/04-joins/group_users | Hierarchy in one table (e.g. hospital → department → group → person). Self-joins, ARRAY_AGG, two-level hierarchy; dim_latest_group_users with tombstone handling for group-level deletes. |
| Rule match on sensors | flink-sql/04-joins/rule_match_on_sensors | Temporal join of sensor stream to static sensor_rules (tenant, parameter, thresholds). Faker-based sensors source. |
1.5 Changelog Mode (Append, Retract, Upsert)¶
| Sample | Path | Description |
|---|---|---|
| Changelog mode (append, retract, upsert) | flink-sql/05-changelog | Orders + products: append vs retract vs upsert. Impact on aggregation, join, dedup. CTAS for enriched_orders, user_order_quantity. Diagrams in docs/. Makefile for deploy/insert. |
1.6 Schema Evolution¶
| Sample | Path | Description |
|---|---|---|
| Schema refactoring (products → discounts) | flink-sql/07-schema-refactoring | PostgreSQL products table refactored: discount moved to discounts table. Flink join products + discounts, support old (inline discount) and new (discount_id) schema. alter_product.sql, pd_discounts.sql, ps_products_v1.sql. |
1.7 Snapshot Query & Search External Tables¶
| Sample | Path | Description |
|---|---|---|
| Snapshot query | flink-sql/08-snapshot-external-query | Confluent Cloud snapshot query: Datagen connector, SET 'sql.snapshot.mode' = 'now', count on append-only table. |
| External table lookup | flink-sql/08-snapshot-external-query | Use KEY_SEARCH_AGG with external table deployed on AWS RDS Postgresql |
1.8 Temporal Joins¶
| Sample | Path | Description |
|---|---|---|
| Temporal joins (versioned table) | flink-sql/09-temporal-joins | Join orders to versioned currency_rates with FOR SYSTEM_TIME AS OF orders.order_time. Confluent Cloud: DDLs, insert orders/rates, behavior when rates arrive late. Local: CSV + temporal_joins.sql. |
1.9 Windowing¶
| Sample | Path | Description |
|---|---|---|
| Tumbling & hopping windows | flink-sql/10-windowing | Tumbling window: distinct order count per minute. Hopping: 10-minute window, 5-minute slide. Uses deduplicated orders from CC marketplace. cc-flink/create_unique_oder.sql, order_per_minute.sql. |
| Grouping messages | flink-sql/10-windowing/grouping-messages | Creating n bulk NDJSON messages from raw |
1.10 Puzzles & Exercises¶
| Sample | Path | Description |
|---|---|---|
| SQL puzzles (overview) | flink-sql/11-puzzles | Highest transaction per day, employees data, table DDLs. Test env: Flink binary or Kubernetes. |
| Compute ETA (shipment) | flink-sql/11-puzzles/compute_eta | ETA from shipment events: source shipment_events, shipment_history (ARRAY_AGG per shipment), join + UDF estimate_delivery. Confluent Cloud; Python UDF mock in udf/. deploy_flink_statements.py, Makefile. |
| Create tables (tx, loans, employees) | flink-sql/11-puzzles | create_tx_table.sql, create_loans_table.sql, data/create_employees.sql, highest_tx_per_day.sql. |
1.11 AI / ML Integration¶
| Sample | Path | Description |
|---|---|---|
| AI agents (anomaly detection) | flink-sql/12-ai-agents | Reefer temperature: Faker source, burst view, ML_DETECT_ANOMALIES (ARMA) in tumbling window. Confluent Flink built-in ML. |
1.12 SQL Execution & Runtimes¶
| Sample | Path | Description |
|---|---|---|
| Flink SQL Quarkus | flink-sql/flink-sql-quarkus | Table API + SQL examples as Quarkus app. Run in IDE or submit JAR to Flink (Docker). |
| Flink Python SQL runner | flink-sql/flink-python-sql-runner | Python-based SQL runner entry. |
| Triage (DDL only) | flink-sql/triage | DDLs: ddl.employees.sql, dd.departments.sql, ddl.jobs.sql. |
2. Flink Java (DataStream API)¶
to rework
All Datastream demos are too old.
2.1 Quickstart & Word Count¶
| Sample | Path | Description |
|---|---|---|
| DataStream quickstart | flink-java/datastream-quickstart | Minimal DataStream v2 job: NumberMapJob. Build, submit to Flink cluster, K8s OSS deployment YAML. |
| Word count (file) | flink-java/datastream-samples/01-word-count | Read file, count word occurrences. FileSource connector. |
2.2 DataStream Samples (my-flink)¶
| Sample | Path | Description |
|---|---|---|
| Word count, filters, joins | flink-java/my-flink | WordCount (file), PersonFiltering, LeftOuterJoin / RightOuterJoin / FullOuterJoin / InnerJoin (persons + locations). Data in data/. |
| Bank fraud | flink-java/my-flink (bankfraud) | Bank.java, BankDataServer.java, AlarmedCustomer.java, LostCard.java – fraud/lost-card style flows. |
| Datastream aggregations | flink-java/my-flink (datastream) | ComputeAggregates.java, ProfitAverageMR.java, WordCountSocketStreaming.java. |
| Kafka telemetry | flink-java/my-flink (kafka) | TelemetryAggregate.java – Kafka source aggregation. |
| Taxi stats | flink-java/my-flink (taxi) | TaxiStatistics.java; test in TestTaxiStatistics.java. Data: cab_rides.txt, etc. |
| Windows (sales) | flink-java/my-flink (windows) | TumblingWindowOnSale.java. Sale data server in sale/. |
| Docker / K8s | flink-java/my-flink/src/main/docker | Dockerfile variants (JVM, legacy-jar, native). |
Note: Some code uses deprecated DataSet API; Table API ports live under table-api/.
2.3 Batch Processing & Table API¶
| Sample | Path | Description |
|---|---|---|
| Loan batch processing | flink-java/loan-batch-processing | DataStream: read loan CSV, stats (avg amount, income, counts by status/type), write CSV. Table API: fraud analysis, optional DuckDB JDBC sink. DataStreamJob.java, TableApiJobComplete.java, FraudCountTableApiJob.java. verify_duckdb.sh, query_duckdb.sql. |
2.4 SQL Runner (JAR)¶
| Sample | Path | Description |
|---|---|---|
| SQL runner | flink-java/sql-runner | Run SQL scripts as Flink job (from Flink OSS examples). JAR with SQL in sql-scripts/ (e.g. main.sql, statement-set.sql). Docker and K8s deployment. |
3. Table API¶
3.1 Java – Confluent Cloud¶
| Sample | Path | Description |
|---|---|---|
| Confluent Cloud Table API | table-api/ccf-table-api | Confluent examples: catalogs, unbounded tables, transforms, table pipelines, changelogs, integration. Example_00_HelloWorld … Example_08_IntegrationAndDeployment, TableProgramTemplate.java. JShell init: jshell-init.jsh. |
| Java Table API (Confluent) | table-api/java-table-api | Join order–customer, deduplication, PersonLocationJoin. Env vars for CC. JShell with pre-initialized TableEnvironment. |
3.2 Java – OSS & Local¶
| Sample | Path | Description |
|---|---|---|
| OSS Table API + SQL | table-api/oss-table-api-with-sql | PersonLocationJoin with persons/locations files. cloud-template.properties. |
| Simplest local Table API | table-api/simplest-table-api-for-local | In-memory table, filter, print. Session job or Application mode. |
3.3 Python Table API¶
| Sample | Path | Description |
|---|---|---|
| PyFlink | table-api/python-table-api | first_pyflink.py, word_count.py – basic Table API in Python. |
4. Local end-to-end demonstrations¶
All demonstrations run on local Kubernetes (Confluent Platform or Apache Flink), Confluent Cloud, or OSS Flink. Each demo follows a standard layout: cccloud/ (Confluent Cloud), cp-flink/ (Confluent Platform on K8s), oss-flink/ (OSS Apache Flink), with a README per folder for goal, status, approach, and how to run.
See the e2e-demos README for the full index. The table below tracks refactoring status, supported environments, README update date, and automation to validate each demo.
4.1 cc-cdc-tx-demo¶
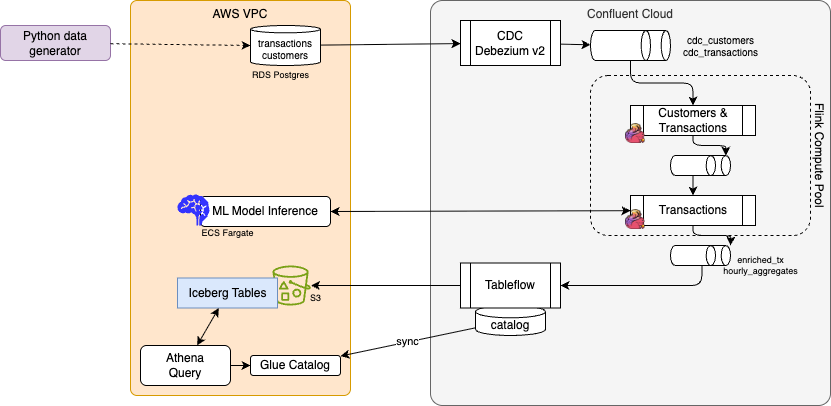
Full Confluent Cloud demo: AWS RDS PostgreSQL → Debezium CDC → Kafka → Flink (dedup, enrichment, sliding-window aggregates) → TableFlow → Iceberg/S3, AWS Glue, Athena. Optional ML scoring via ECS/Fargate. Terraform: RDS, Confluent, connectors, compute pool; separate Terraform for Flink statements.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | ✓ | — | — | — | Partial (IaC + Makefiles; no single end-to-end validate) |
Path: e2e-demos/cc-cdc-tx-demo
4.2 cdc-dedup-transform¶
Qlik Replicate CDC → Flink: raw CDC envelope (key, headers, data, beforeData), filter/dedup, extract by operation (REFRESH/INSERT/UPDATE/DELETE), DLQ, business validation, S3/Iceberg sink. Propagate DELETE to sink.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | ✓ | — | — | — | Partial (Makefiles per layer; no single validate) |
Path: e2e-demos/cdc-dedup-transform
4.3 cdc-demo¶
PostgreSQL (CloudNativePG) + Debezium CDC on K8s → Kafka → Flink SQL. Tables: loan_applications, transactions. Debezium envelope, message.key.columns, Flink DDL. Makefile: demo_setup, deploy_connect, demo_run, deploy_flink, flink_sql_client.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | ✓ | — | — | Partial (make demo_setup / demo_run / demo_cleanup; no automated validation) |
Path: e2e-demos/cdc-demo
4.4 cdc-tableapi-to-silver¶
Mock Debezium envelope processing: raw accounts and transactions as after and before field. Extract the schema from ROW as silver (src_accounts, src_transactions), then basic dim_account, and fact fct_transactions enriched with account informations. Python code to deploy statments, delete and drop tables and run validation SQLs, all based on the Confluent Cloud REST API (a simple version of shift_left tools).
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | ✓ | — | ✓ | — | In 3 scripts |
Path: e2e-demos/cdc-tableapi-to-silver
4.5 dedup-demo¶
Deduplicate product events: Flink SQL (ROW_NUMBER dedup, upsert to src_products) or Flink Table API (Java, K8s). Python producer generates intentional duplicates.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | ✓ | ✓ | — | Partial (scripts/Makefile per variant; no single validate) |
As of now as the WITH part of each SQL will be different according to the target environment, the Apache Flink and CP Flink are not completed.
Path: e2e-demos/dedup-demo
4.6 e-com-sale¶
Real-time e-commerce: user actions, purchases, inventory. Flink job: revenue per minute, top products, low-inventory alerts, recommendations. Python simulator, K8s topics + Flink app (CMF or OSS).
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | ✓ | ✓ | — | Manual (make build / create_flink_app; no automated validation) |
Path: e2e-demos/e-com-sale
4.7 e2e-streaming-demo¶
Flink SQL (Alibaba Tianchi–style user_behavior): Kafka source, TUMBLE windows (hourly buy count → Elasticsearch), cumulative UV, top categories via temporal join to MySQL. Docker Compose.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | — | ✓ | — | Manual (docker compose + manual SQL; no validate script) |
Path: e2e-demos/e2e-streaming-demo
4.8 external-lookup¶
Payment events (Kafka) enriched by async lookup to external DB (claims). Flink left join; success → enriched-payments, failures → failed-payments. DuckDB + API, event-generator, Flink app on K8s (CMF).
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | ✓ | — | — | Partial (make prepare_demo / run_demo; no automated assertion) |
Path: e2e-demos/external-lookup
4.9 flink-to-feast¶
Real-time windowed aggregation → Feast online feature store; ML model consumes features. Confluent ML_PREDICT, feature_repo, kafka_consumer, model_serving.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | ✓ | — | — | — | Manual (multi-component; no single validate) |
Path: e2e-demos/flink-to-feast
4.10 flink-to-sink-postgresql¶
Flink joins two topics (e.g. orders + shipments) → output topic → Kafka JDBC Sink → PostgreSQL. Docker Compose or K8s.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | ✓ | ✓ | — | Manual (start stack, send data, verify in PG manually) |
Path: e2e-demos/flink-to-sink-postgresql
4.11 json-transformation¶
Truck rental: raw-orders + raw-jobs Kafka topics → Flink SQL or Table API → nested OrderDetails (EquipmentRentalDetails, MovingHelpDetails). Producer and schemas at root.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | ✓ | ✓ | — | — | Partial (Makefile deploy; no automated SQL validation) |
Path: e2e-demos/json-transformation
4.12 savepoint-demo¶
Stop/restart stateful Flink job with savepoints. Producer writes (sequence_id, value=2) to Kafka; Flink SQL sums value. Minikube, Confluent Platform.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | ✓ | — | — | Manual (README steps; no scripted validate) |
Path: e2e-demos/savepoint-demo
4.13 sql-gateway-demo¶
Flink SQL Gateway: start cluster and gateway, create CSV source table, deploy DML, assess results. Local/OSS only.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | — | ✓ | — | Manual (no scripts) |
Path: e2e-demos/sql-gateway-demo
4.14 agentic-demo¶
Flink Agents (Python): flink-agents package with local Flink. Python 3.11 + uv, PYTHONPATH for JVM.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | — | ✓ | — | Manual (README only) |
Path: e2e-demos/agentic-demo
4.15 package-event-cutoff¶
Package morning cutoff (11:30): emit only when expected_delivery changes; at cutoff, proactively emit for packages with no recent event; ETA computation with UDF. Shared sql-scripts, tests, eta_udf.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | ✓ | — | — | 03/03/2026 | Partial (run_use_case_½/3.sh; validate SQL exist but no single end-to-end script) |
Path: e2e-demos/package-event-cutoff
4.16 perf-testing¶
End-to-end performance assessment: configurable producer → Kafka → Flink job(s) (sql-executor, datastream, flink-sql). Throughput and latency metrics. Scripts for topics, run producer, deploy jobs.
| Status | cccloud | cp-flink | oss-flink | Updated | Full automation |
|---|---|---|---|---|---|
| Ready | — | ✓ | ✓ | — | Partial (build + scripts; no automated metric assertion) |
Path: e2e-demos/perf-testing
Legend: ✓ = deployment folder present with README. Updated = date from demo root README (e.g. "Created DD/MM/YYYY") when present; otherwise —. Full automation = one-command (or scripted) deploy + validation that the demo works; Partial = scripted deploy or validate only; Manual = README steps only.
Public repositories with valuable demonstrations¶
- apache flink 2.x Playground
- Personal Flink demo repository for Data as a product, ksql to Flink or Spark to Flink automatic migration test sets.
- Confluent Flink how to
- Confluent demonstration scene: a lot of Kafka, Connect, and ksqlDB demos
- Confluent developer SQL training
- Flink Confluent Cloud for Apache Flink Online Store Workshop, support Confluent enablement Tours.
- Confluent Quick start with streaming Agents
-
lab 3- Agentic Fleet Management Using Confluent Intelligence
-
Demonstrate Flink SQL test harness tool for Confluent Cloud Flink.
-
Shoes Store Labs to run demonstrations on Confluent Cloud.
- Confluent Cloud and Apache Flink in EC2 for Finserv workshop
- Online Retailer Stream Processing Demo using Confluent for Apache Flink
Interesting Blogs¶
- Building Streaming Data Pipelines, Part 1: Data Exploration With Tableflow
- Building Streaming Data Pipelines, Part 2: Data Processing and Enrichment With SQL