Conduct system design¶
Methodology¶
-
Verify the goals
- Why we are doing this application / solution?
- Who is the end user?
- How they will use the system and for what purpose?
- What are the expected outcomes and what are the inputs?
- How to measure success?
-
Think about end user's experience - working backward
-
Establish scope
- list some potential features
- Are we looking at end to end experience or API design
- type of client application or device
- Do we require authentication? Analytics? Integrating with existing systems?
-
Design according to scale
- What is the expected read-to-write ratio?
- what volumes in term of transactions/ requests
- How many concurrent requests should we expect?
- What’s the average expected response time?
- What’s the limit of the data we allow users to provide?
- Do we need to expose read data in different geographies?
-
Defining latency requirements
- how fast is fast enough?
- Try to express in SLA language: 100ms at 3-nines - 99.9% of availability is around 9h down per year. 5 nines is 5 minutes down.
Information
- AWS offers TCP connections up to the edge and then use AWS private backbone (global accelerator), which improves performance by 60%
- Try to use Real User Monitoring tool to measure network performance
-
Try to measure:
- Throughput – the amount of data or number of data packets that can be delivered in a predefined timeframe,
- Latency in connection – also called round-trip times or RTT,
- Network jitter – the variability over time of the network latency, and
- Packet loss. Get 1,000 samples every hour for a day.
-
Apache Bench helps to test throughput and latency of HTTP servers
- Round-Trip Time (RTT) is the total time that it takes a data packet to travel from one point to another on the network and for a response to be sent back to the source. It is a key perf metric for latency. Ping measure ICMP RTT.
-
From high level to drill down
- Start by high level view
- Cover end to end process
- Go when necessary to detail of an API, data stores,..
- Look at potential performance bottle neck
-
Review data structure and algorithms to support distributed system and scaling
-
Be able to argument around
- What type of database would you use and why?
- What caching solutions are out there? Which would you choose and why?
- What frameworks can we use as infrastructure in your ecosystem of choice?
-
Do not be defending
-
Demonstrate perceverance - determination: internal drive to search for a solution - collaboratively.
- Behavioral interviewing, tell the stories when you demonstrate perceverance.
- Independent thought: getting your solution from your own experience
- Independent learning
- Never give up and never surrender
-
Tech skills matter but they are just table stakes
- Demonstration self motivated: bring with your own.
- Do not be the guy "let me google for you!"
- They do not want to see people following step by step instructions/ recipes, because it demonstrates you cannot solve new problem
- Work as no value until demonstrate to customers
Scalability¶
Single server design¶
- Unique server with HTTP and Database on a unique server. Simple but has a single point of failure: impact is to change DNS routing with new server.
- Separate out the DB help to scale DB and server independently.
Vertical scaling¶
Use bigger server. Get a limit by hardware size. Still single point of failure. Pros is the limited number of things to maintain.
Horizontal scaling¶
Load balancer sends traffic to a farm of servers. This is easier if the web server is stateless, that means we do not keep state of the conversation. Any server can get request at any time.
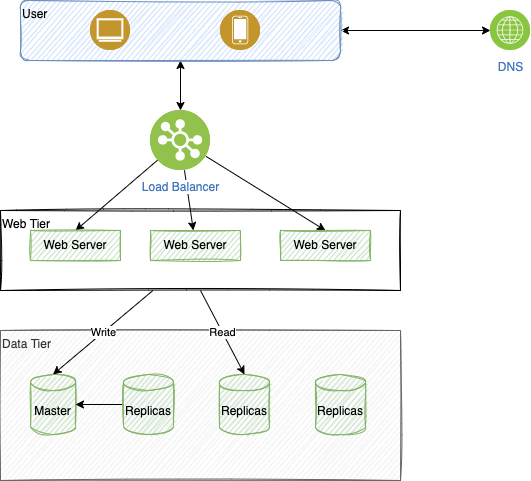
A master database generally only supports write operations. A slave database gets copies of the data from the master database and supports read operations.
By replicating data across different locations, the website remains in operation even if a database is offline as it can access data stored in another database server.
This is important to remember that user session needs to be kept, for example to avoid re-authenticate if the new request reaches another web server. Stateful web tier is not encouraged for scalability. So stateless architecture is used, where HTTP requests from users can be sent to any web servers, which fetch state data from a shared data store. The shared data store could be a relational database, Memcached/Redis, NoSQL,...
Failover¶
See also DR article and data replication blog.
To access transparently server on two different data centers, we use geoDNS, which is a DNS service that allows domain names to be resolved to IP addresses based on the location of a user. In the event of any significant data center outage, we direct all traffic to a healthy data center.
Important challenges to consider are:
- Traffic redirection: Effective tools are needed to direct traffic to the correct data center.
- Data synchronization: Users from different regions could use different local database or cache. In failover cases, traffic might be routed to a data center where data is unavailable.
Cold standby¶
- periodic backup
- restore backup on DR site
- reconnect front end server to new DB server
- Data gone after the database backup is lost
- Take time to get the new server up and running.
- RPO can be day (snapshot frequency) - RTO hours
Warm Standby¶
- Continuous replicated: the DB is ready to get connected
- Tiny window to get data loss
- Still using vertical scaling
Hot Standby¶
- Write to both servers simultanuously
- Can distribute the read
Sharding database¶
- Horizontal partition of the database
- Each shard has its own replicated backup
- Hashcode is used to allocate data to shard
- Combining data from shards is more complex. So need to minimize joins and complex SQL
- Organize data in key value, to easy the hashing.
- Value can be an object and let the client being able to interpret.
For example MongoDB uses mongos on each app server to distribute the data among a replica set. Replica sets are managed by primary server and secondary servers manage shards. In case of primary server fails, the secondary servers will elect a new primary. Primary looks like a SPOF, but it recovers quickly via the secondary taking the lead. Need at least 3 servers to elect a primary. Traffic is partitioning according to a scheme, which is saved in a config servers.
Cassandra uses node rings, a shard is replicated multiple times to other nodes, but each node is a primary of a shard. So data needs to be fully replicated, and eventually will be consistent.
Resharding is a challenge for the database.
NoSQL really means sharded database, as some DB can support most of SQL operations.
Need to address how to partition the raw data for best performance. For example organize the bucket or folder structure to simplify future queries: organize them by date, or entity key...
De-normalizing¶
We normalize the data to use less storage and updates in one place. But need more lookups.
De-normalize duplicates data, use more storage, but uses one lookup to get the data, which leads to have harder update.
To assess what is a better fit, start with normalize, as we need to think about the customer experience, and consider different types of query.
Data lake¶
Throw data into text files (json, csv...) into big distributed storage system like S3. Which his named data lake. It is used in common problem like Big Data and unstructured data.
We can also query those data by adding an intermediate components to create schema from the data and support queries. (Amazon Glue like a schema discovery) and Amazon Athena to support queries and Redshift to do distributed warehouse with spectrum to query on top of s3.
| Product | Description |
|---|---|
| AWS S3 | Service. data lake with s3. 11 9's% for durability. Pay as you go. Offers different level of backup with Glacier |
| Google Cloud Storage | introduction. Use hierarchy like: organization -> project -> bucket -> object. Tutorial |
| IBM Cloud Object Storage | doc |
| Azure Blob | doc |
CAP & ACID¶
- Atomicity: either the entire transaction succeeds or the entire thing fails
- Consistency: All database rules are enforced, or the entire tx is rolled back. Consistency outside of ACID is really to address how quickly we get the data eventually consistent after a write.
- Isolation: no tx is affected by any other tx that is still in progress.
- Durability: once a tx is committed, it stays, event if the system crashes.
CAP theorem: We can have only 2 of the 3: Consistency, Availability and Partition tolerance. With enhanced progress, CAP is becoming weaker, but still applies. A is really looking at single point of failure when something going down. MongoDB for example may loose A for a few seconds maximum (find a new primary leader), which may be fine.
- AC: is supported by classical DBs like mySQL, postgresql
- AP: Cassandra: C is lost because of the time to replicate
- CP: Mongodb, HBASE, dynamoDB: strong consistent read request, it returns a response with the most up-to-date data that reflects updates by all prior related write operations to which DynamoDB returned a successful response, so network delay or outtage does no guaranty A.
Single-master designs favor consistency and partition tolerance.
Caching¶
Goal: limit the access to disk to get data, or go over the network.
Solution is to add a cache layer in front of the DB to keep the most asked data, or the most recent... Caching services can be used to be able to scale horizontally.
Every cache server is managing a partition of the data, using hashing.
Appropriate for applications with more reads than writes. Expiration policies dictate how long data stays in cache. Avoid data go stale.
Hotspot may bring challenge for cache efficiency, need to cache also on load distribution and not just on hash. Finally starting the cache is also a challenge, as all requests will go to the DB.
Inconsistency can happen because data-modifying operations on the data store and cache are not in a single transaction. When scaling across multiple regions, maintaining consistency between the data store and cache is challenging.
Manage the cache size with different eviction policies:
- LRU: least recently used. HashMap for key and then doubly linked-list, head points to MRU and tail points to the LRU. Evicts data that hasn't been accessed in the longest amount of time once memory for the cache fills up.
- LFU: least frequently used.
- FIFO
Redis, Memcached, ehcache. AWS Elasticache
Content Delivery Networks¶
when a user visits a website, a CDN server closest to the user will deliver static content. CDN distributes read data geographically (css, images, js, html...), can even being used for ML model execution.
Load balancers and caching technologies such as Redis can also be parts of low-latency designs, but are not specifically for the problem of global traffic.
CDNs may run by third-party providers, and you are charged for data transfers in and out of the CDN.
AWS cloudfront is a CDN.
Resiliency¶
Assess what could happen is a blade/ server, a rack, an AZ, a data center, a region goes down. Mission critical applications should not loose data. Use 3 tiers app classification schemas.
Use Geo-location load balancer then geo LB.
Need to plan for capacity to be able to get traffic from failed region to 'backup region'.
Secondary replicas should be spread to different servers, racks and then data centers.
Balance budget over availability. Amazon with infinite money does over-provisioning.
HDFS¶
Files are broken into blocks. Blocks are replicated within the cluster. Replicas are rack aware.
Clients try to read from nearest replica.
The Name node coordinate the blocks placement operations. For HA the name nodes is a 3 nodes cluster, so a single point of failure for a very short time period.
If a client app is running in the same server as HDFS the data it accesses may be moved to it.
SLA¶
- Durability: % chance of losing data
- Latency to get the time for a service to return a response to a request. 99.9% response time is under 100ms
- 99.9999% availability is 30 s down time. 99% is 3.45 days out
Big Data¶
Apache Spark¶
Goal: parallelize processing on big amount of data.
On classical HADOOP 2 - architecture for big data:
- HDFS to distribute data
- Yarn (yet another resource negotiator) to manage access to the data in HDFS
- MapReduce processing (old google - map to extract data and reduce to combine for aggregation) or Spark.
Spark is a replacement of MapReduce. It decides how to send processing to run it in parallel. Work with in memory caching. Compute aggregation on data at rest. You can use it for interactive queries with Spark SQL.
The drive program (or SparkContext) is the one who define what are the input, output, and the processing to do. They are scheduled by Spark to run within a cluster. SparkContext sends app code to executors.
Flink¶
Scalable streaming platform for inbound and outbound data. See dedicated study
Cloud computing services¶
| AWS | Azure | ||
|---|---|---|---|
| Storage | s3 | cloud storage | Disk, blob, data lake |
| Compute | EC2 | Compute engine | VM |
| NoSQL | DynamoDB | BigTable | CosmosDB / Table Storage |
| Containers | Kubernetes / ECR / ECS | Kubernetes | Kubernetes |
| Data streams | Kinesis | DataFlow | Stream Analytics |
| Spark / Hadoop | EMR | Dataproc | Databricks |
| Data warehouse | RedShift | BigQuery | Azure SQL / Database |
| Caching | ElastiCache (Redis) | Memorystore (Redis or memcached) | Redis |
Mock system design interviews¶
URL shortening service¶
- Talking about bit.ly: a service where anyone can shorten an existing URL and then the service is managing redirecting the traffic.
- what sort of scale?
- Any restriction on chars to be used?
- How short is short?
The approach is to design the potential API, then the components, present a data model for persistence and then address the redirect.
| Verb | APIs |
|---|---|
| POST | New long url, user-id returns short url and status |
| POST | Propose vanity long url, vanity URL, user-id returns status |
| GET | mapping between long and short |
| PATCH | update: short URL, long URL, user id, returns status |
| DELETE | short URL, user id return status |
| GET | short URL, redirect to long URL |
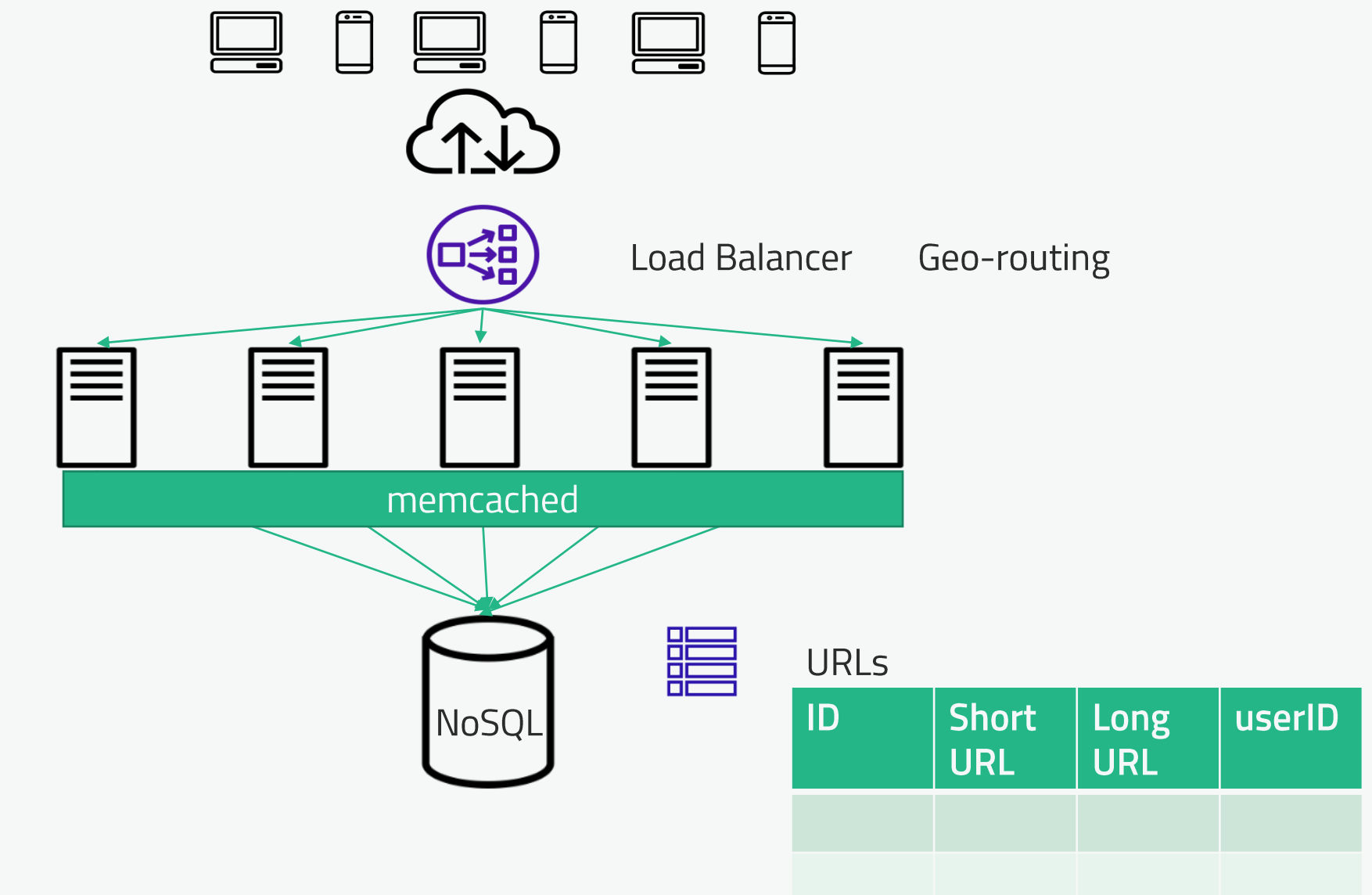
To perform redirect, the HTTP response status may be 301 or 302. 301 is a permanent redirect, so intermediate components will keep the mapping. But if you want to keep analytics (search engine) on your web site traffic, you want to know how many redirects are done per day, therefore 302 is a better choice. This is a temporary redirect.
A restaurant system like OpenTable¶
As customer I want to:
- specify the number of members for the dining party.
- select a time slot and specify a location.
- select a restaurant by name.
- select a type of food.
- book the table for the selected time slot, by specifying phone number and email address.
- specify how to be contacted when closer to the time (sms).
- register as a recurring user to get royalty points.
Other customers of this application will be restaurant owners, who want to see their booking, but also get more information about the customers, the forecast, and the number of search not leading to their restaurant. May be expose their menu. Get statistic on customer navigation into menu items.
NFR: thousands of restaurants, national, millions of users.
Need to scale and be reliable. Cost is not an issue.
Data model:
- search: location, time - date, party size, type of food.
- list of restaurants.
- list of time slots.
- reservation: restaurant, party size, time slot, email, phone number, type of contact.
- return booking status with reservation ID to be able to cancel it in the future.
So we need:
- Restaurant to describe physical location, # tables.., how they can group tables for bigger party.
- Customer representing physical contact.
- A schedule per 15 mn time slots, table list per restaurant.
- Reservation to link customer to restaurant by using their primary keys.
- A Search: time slot, party, location.
- The reservation function need to take into account capability of the restaurant on how to organize tables.
This is a normalized data model, as it is easier and really for reservation, there is one transaction on a simple object. Restaurant and customer are read models in this context.
Outside of the authentication, lost password APIs... we need few APIs to support the reservation:
| Verb | APIs |
|---|---|
| GET | search with query? location, date, party |
| POST | reservation |
| DELETE | reservation |
Other APIs may be needed to do CRUD for each business entities: restaurants
The servers are scaled horizontally, rack and AZ allocated, and even geo-routed.
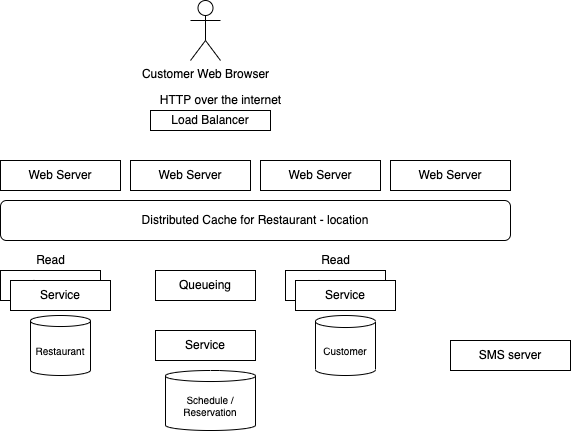
DB system may be no sql based, and can be highly available and support horizontal scaling too.
Web Crawler for a search¶
Problem: build a web crawler tool to prepare data for semantic search:
Need to parse html, keep text only, may be pictures in the future, billions of web pages, and run every week. Need to update of existing page refs if they changed.
HTML = text + ref to URL
Singleton web crawler will put links into a LIFO pile. If we consider the web crawling as a graph navigation, we want to do BFS, so we need a pile as data structure.
As we need to update crawled content every week, we can, in fact, run all the time with a single instance of the crawler. The solution uses batch, as no end-user uses the system. Except that, we still need to provide metrics to display coverage: pile size, total number of page processed, link occurrence...
Need to avoid looping into pages, so need to keep the visited pages as well. If we need to run in parallel, then pile and visited page tree will be shared and distributed. So we need a partition key, may be a hash of the url.
The solution may look like in the figure below:
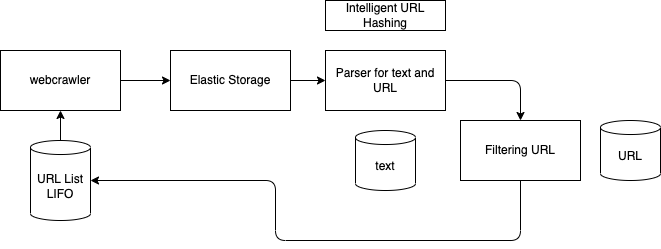
- Web Crawler using HTML parser and text extraction
- Save in a distributed cloud storage the source page, and pictures
- Extract the URLs and put them in a Pile data structure. Hash the URL. Filter out URLs already processed. Add the new URLs in the Queue
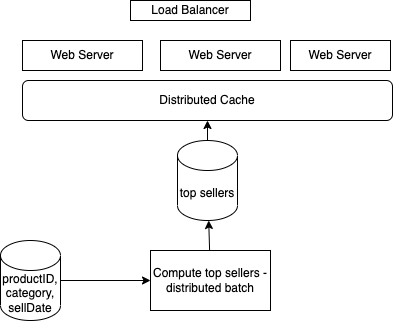
Top sellers in e-commerce¶
Present the top sellers per category / sub-category. We can have thousand of request per second.
- top seller means trending: so # of sell over a time period.
- time period is variable for low sell item, so item sold few time per year, needs to be visible for a category. We can also use a weight algorithm to put less impact on older sells.
The update can be done few time a day for most active category.
The new customer experience includes: after searching and looking at a category of items, the system returns a list of top seller under the product description.
Sell Object is a product ID, category, date of sell.
Batch processing computes the top sellers per category, and saves it in distributed cache.
The amount of data is massive so querying per category and sort by date of sell will put stress to any SQL database. We can replicate the DB and work on the data warehouse, or adopt cloud object storage bucket with category being the bucket. For the job processing, we could use Flink or Spark, to compute the top-sell product.
Job will run in parallel and flink will distribute data. It will compute for each product a score based in (t - purchase time) time, decaying older sells. We sort by this score.
The top-seller data store does not need to support a big amount of data, may be keep the top 20 or 50 items per category, and may be hundred of thousand of category. Distributed document oriented Database can be used.
To support scaling and low latency at the web page level, we need distributed caching, and scale web server horizontally. Here is a component view:
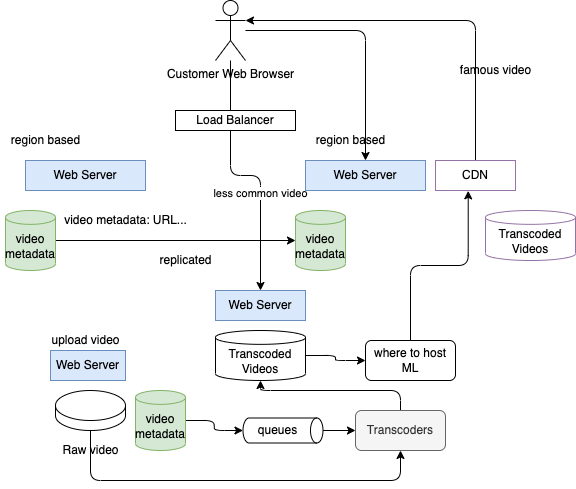
Video sharing service¶
Some thing like youtube.
- anybody in the work can upload video, and anybody can view it.
- massive scale.
- Users and videos in billions .
- Video upload and playing back those videos.
Feel free to use existing services.
Customer centric design:
-
Watching user: video search, video metadata and video player
- Need a web server returning video URL and metadata: name, url, length, author, thumbnail picture,
- Big table to keep metadata. Key value pair. Easy to replicate and cache in different geographies
- Video needs to be close to user, like a CDN, with transcoded videos. Need distributed storage, and able to scale at billion of file. File between 50 Mb to 4 Gb may be.
- Object Store can be used for the video persistence. The key for each video may include compression type, resolution...
- The video player will be able to switch between resolution, or advance in the video time.
-
To reduce the cost of this system as CDN and object storage are not cheap.
- can classify videos that will be in CDN versus one staying on the servers.
- Long tail meaning faming - popularity -
- predict a likelihood to get a video watch today so it can be pushed to the CDN
- CDN per region per language.
-
for uploading video, users create metadata, and then upload the raw video in a distributed storage, then the video needs to be transcoded to the different format. We can use queueing approach to get the transcoders always feeded and also being able to run in parallel.
- Metadata needs to keep the state of if the video transcoding is complete or not, to avoid publishing reference to video not yet transcoded.
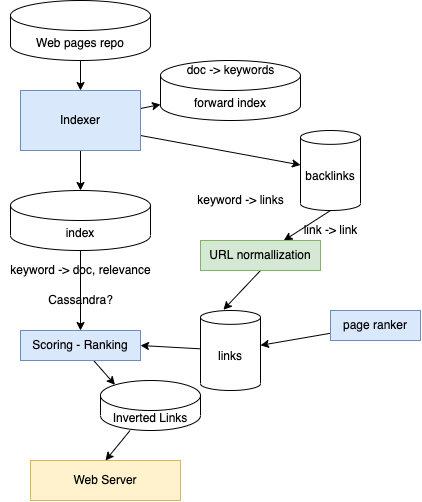
Designing search engine¶
- Like google, billions of people and billion of pages
- The problem is really how to get accurate results for a given query.
-
Start from a reporting database with URL of pages
-
Need to avoid people adding thousand of the same keyword in a unique page to get the hit.
- Accurate result means the search will return a list of the most likely page what the user's expects. So need to get metrics on page accuracy.
- we can compute how many times a user perform a search after page results were displayed within a specific time window.
Elaborate an algorithm:
- TF/IDF : term frequency / document frequency to assess how a term is relevant across documents. It works fine for a small document base. With internet scale the denominator is mostly impossible to compute.
- To address a better solution we need to thing about what to present to the user: a list of top 10 hits. So we need an inverted index: searched keyword -> list of pages sorted by relevance.
- Page rank was developed for Google to assign a rank based on number of link to the page.
-
How to evaluate relevance of a term within a doc: terms in the documentation, the position, the title, the font size, heading, formatting, metadata attached to the document.
-
Starting for the repository of web pages
- Need to build a forward indexing to extract word count in document, then reverse it to build for word -> documents list
- Then compute back links: the link reaching a given page
BPEL to microservices¶
Taking into source a BPEL flow like the one below, how do you migrate this application logic to a microservice architecture, may be event-driven?
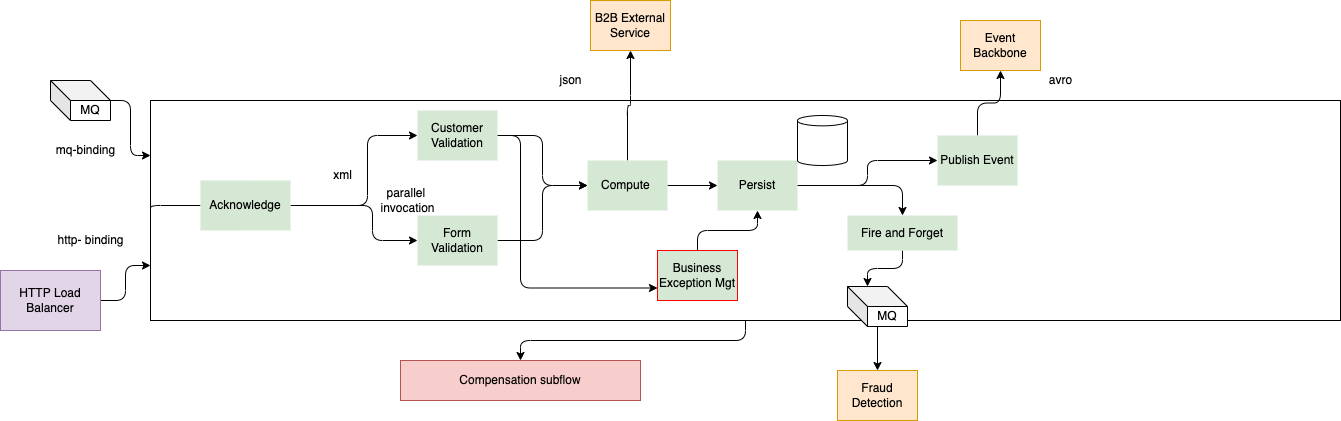
- Input can come from HTTP SOAP requests or messages in queue
- Green components are Service Component Architecture services
- Customers validation, and persistence can be retried multiple times
- With BPEL engine state transfer will be persisted to the process server database.
- The big white rectangle represents an orchestrator
- Acknowledgement service is to send the customer a message, so we do not want to send duplicate messages
- B2B call is idempotent
- Generate a unique id as part of the response: tx_id
- Exception is about business exception so will be defined inside of any business service.
- Exception management may trigger human activities to clean the data, gather more information.
- Compensation flow: if persistence fails, we want to roll back the exception message persistence and restarts from the point before the parallel processing. There are points in the process where we can restart a process, but they are points where the only solution is to cancel the full case.
There is no mention that the flow is part of an external transaction, so to avoid loosing message as soon as the flow gets http soap request or message from queue, it needs to persist those messages and starts the process of customer validation, form validation... If this STP takes 5 seconds to run, it is possible to loose data.
HTTP response needs to be returned, so is this flow needs to be terminated before sending the response? If not it means the process will take more time, and so there is a need to be able to contact the person / submitter that something went wrong.
One of the question is is this white big rectangle could be part of a 'transaction' so needs to offer rolling back state controlled by other.
Saga: is the solution for distributed long running transaction. In Saga, a compensating transaction must be idempotent and retryable.
Saga as atomicity, consistency, durability but is not isolated. Kafka and event sourcing can be user to implement the SAGA. The event is the source of trust. Kafka is the data base for this saga transaction. What does it mean to be consistent with event sourcing?
The Saga Execution Coordinator is the central component to implement a Saga flow. It contains a Saga log that captures the sequence of events of a distributed transaction. For any failure, the SEC component inspects the Saga log to identify the components impacted and the sequence in which the compensating transactions should execute.
For any failure in the SEC component, it can read the Saga log once it’s coming back up. It can then identify the transactions successfully rolled back, which ones are pending, and can take appropriate actions:
In the Saga Choreography pattern, each microservices that is part of the transaction publishes an event that is processed by the next microservice. To use this pattern, one needs to make a decision whether the microservice will be part of the Saga. The Choreography pattern is suitable for greenfield microservice application development.
With Camel SAGA the Saga EIP implementation based on the MicroProfile sandbox spec (see camel-lra) is indeed called LRA that stands for "Long Running Action".
There is another solution that it is purely on top of Kafka: the Simple source is an open source project for event sourcing with Kafka and Kafka Streams which can be used for SAGA.
Microprofile Long Running Action is the supported approach in Java to do SAGA. This project presents how to use LRA in the context of refrigerator contrainer shipping solution.
While this project implements Saga choreography with Kafka.
Music tracking¶
Problem: given an API to track a certain user listened to a certain song, build a system to track the top 10 most listened to songs and albums in the last week (hours, day, week, month, years aggregations are needed).
Use cases: - user plays song. This API tracks the song played at a certain time by a certain users. - playing a song creates an event of start time and song played by who - The list of top 10 songs needs to be updated every hour
Scale: - 400 registered users - 40% are active users - Average 2 hours listening every day. Will depend of the population age. - 70 millions of songs. 60 songs added every day - traffic around 200 query per second can grow to 1000qps
-
Components: Add queueing, pub/sub after the API gateway to push song start record with other information of the user. The goal is to decouple the downstream processing from the write API.
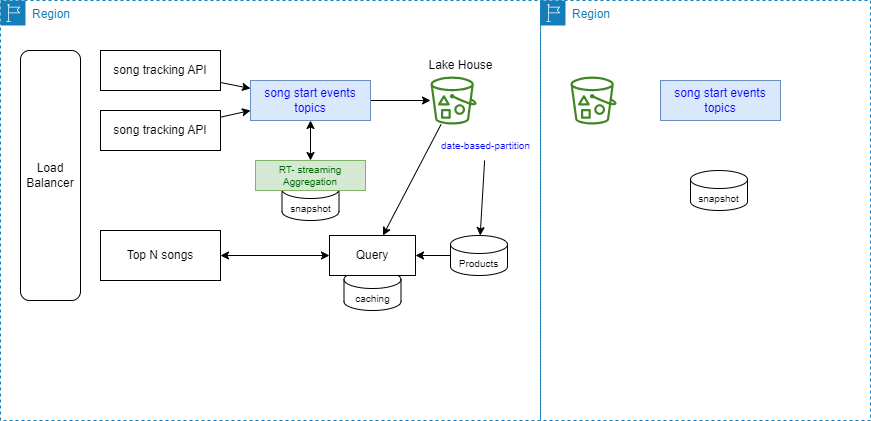
The 'start-song -event' includes user_id, song_id, timestamps, device_reference. There will be a stop-song-event, with the same data. Stop event may not be relevant for this use cases.
The aggregation will be: count the number of event with the same song_id over 60 minutes time window, report this aggregation to a persisted row: date-hours - song_id - count table in Lake House.
-
Application Flow: event to kafka partition can be allocated on the song_id. So all events avout a sond will be in the same partition. We can have hundred of partitions so scale the number of streaming processing. Once event arrived in kafka partition it has also a timestamp. We can add stateful processing to compute the aggregate per minutes or hours. As we also needs to compute larger time windows, we can do some push the aggregation to lake house persistence. Lake House hasa protocol to query data at rest, in cloud object storage format, parquet format.
-
Scaling: adopting a messaging system will help scaling streaming processing. The cloud object storage will help to scale the number of object to persist. The current estimated size it quite low:
-
Resiliency: multi-region deployment, load balancers, active-active capacity on both regions to support failing